


Forensic IDP
Identification of fraud in the automated processing of documents

In order to drive the digitalisation of the German economy through web-based customer and citizen services, more and more documents are being processed fully or partially automatically using Intelligent Document Processing (IDP). This speeds up and simplifies processes, but the low level of human involvement opens the door to fraud, as documents usually do not contain security features such as watermarks, signatures cannot usually be matched or documents can be manipulated after they have been signed.
Research Objective
The objective of the project is to develop the first “Intelligent Document Processing” solution (IDP), which not only extracts all relevant information from documents, but also assesses whether the document has been manipulated.
This enables companies to automate their processes without suffering economic damage from counterfeiting.
This enables companies to automate their processes without suffering economic damage from counterfeiting.
Background
Before the automated processing of documents, the focus of fraudsters was on forging documents in such a way that human auditors would not notice.
Due to automated solutions, however, the focus today is on frauds that are invisible to digital forensic analysis and thus represent a cyber attack. Here, modern image editing programmes such as Adobe Photoshop facilitate fraud through a variety of tools. For example, numbers and letters can be easily copied within or across documents, content can be deleted and resulting gaps filled, or new text can be inserted with an appropriate look. As a result, attackers can increase amounts to get a higher refund, falsify dates to resubmit invoices, or alter vendor data (name/address) and service descriptions to fit the refund criteria.
Due to automated solutions, however, the focus today is on frauds that are invisible to digital forensic analysis and thus represent a cyber attack. Here, modern image editing programmes such as Adobe Photoshop facilitate fraud through a variety of tools. For example, numbers and letters can be easily copied within or across documents, content can be deleted and resulting gaps filled, or new text can be inserted with an appropriate look. As a result, attackers can increase amounts to get a higher refund, falsify dates to resubmit invoices, or alter vendor data (name/address) and service descriptions to fit the refund criteria.
Document Fraud Detection by natif.ai
In contrast to existing methods of fraud detection, we can draw on a fully functional document extraction system that can be flexibly adapted to new document formats.
To implement this, a fraud detection component is integrated into each step of our document analysis pipeline so that the forgery detection directly benefits from the learned knowledge about the document content. We therefore call the overall system ForensicIDP. The project thus falls into the highly topical research area of securing AI-based processes.
To implement this, a fraud detection component is integrated into each step of our document analysis pipeline so that the forgery detection directly benefits from the learned knowledge about the document content. We therefore call the overall system ForensicIDP. The project thus falls into the highly topical research area of securing AI-based processes.
We build fraud detection directly into our own Optical Character Recognition (OCR) by changing the optimisation function of the Deep Learning model from reading only to simultaneously reading and detecting counterfeits. In addition to OCR, we also add fraud detection to our Named Entity Recognition (NER) to learn to simultaneously classify tampered entities and identify forgeries.
Our technology also carries out plausibility checks and can detect image-processing-perfect counterfeits in terms of content, for example if articles are too expensive, the total does not correspond to the sum of the individual articles, or a trader has a different company headquarters according to the database.
It also detects conspicuous pixel patterns that indicate a fraud. It is not only about detecting conspicuousness in places where there is text (e.g. because the text is minimally offset), but also about detecting places where there is no text (e.g. because the attacker has copied background over text in order to delete it).
It also detects conspicuous pixel patterns that indicate a fraud. It is not only about detecting conspicuousness in places where there is text (e.g. because the text is minimally offset), but also about detecting places where there is no text (e.g. because the attacker has copied background over text in order to delete it).
Content Check
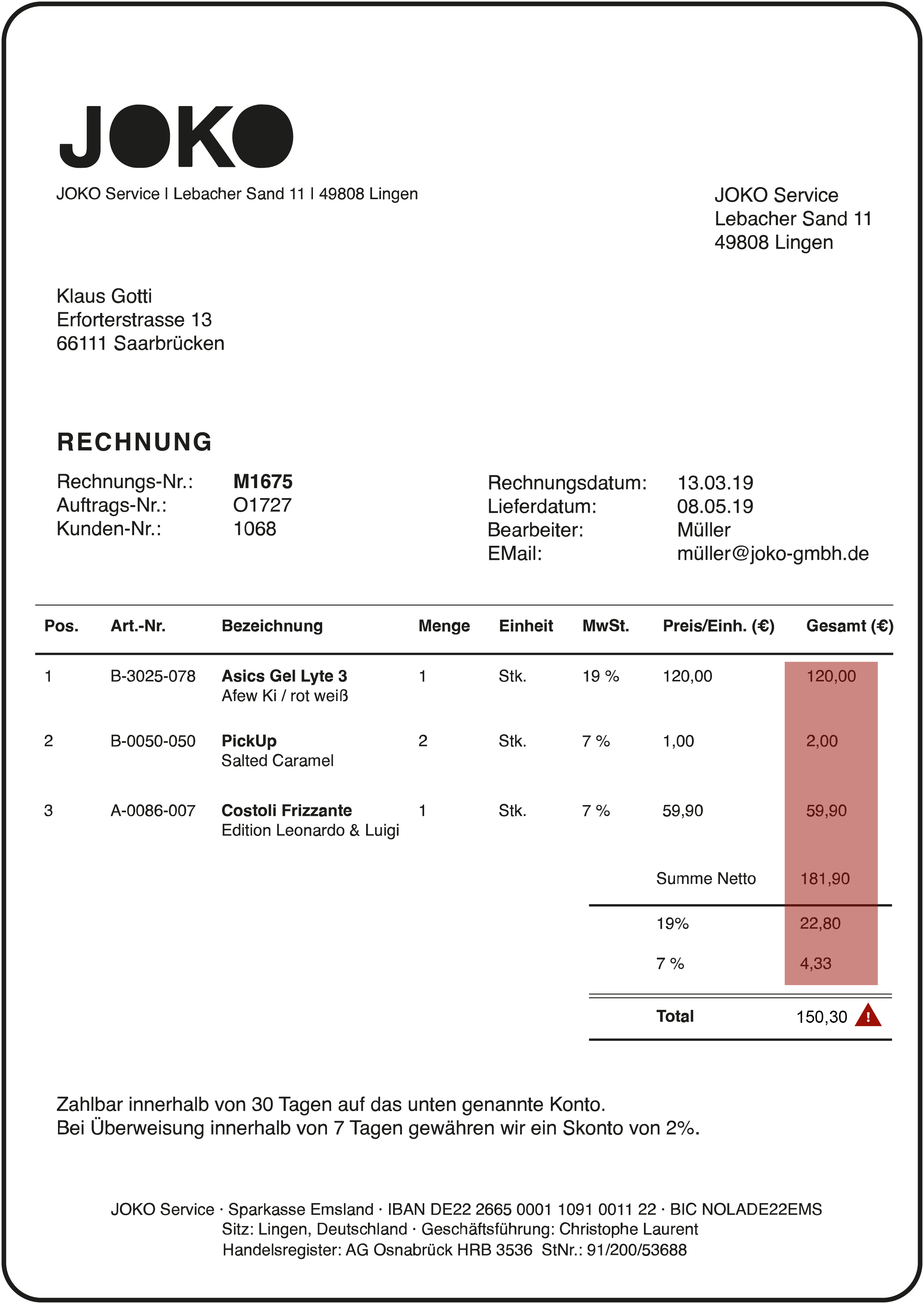
The total shown does not match the total of the individual items including tax.
Pixel Check

The marked areas show conspicuous pixel patterns that indicate manipulation.
Current Status
The individual modules have already been developed and are currently being integrated. The technology is being tested internally and the results are very promising.
The first pilot customers are also testing the new technology and giving natif.ai feedback on it.
The first pilot customers are also testing the new technology and giving natif.ai feedback on it.
Contact person for questions about the research project: