Form automation
with AI
What we do
Forms still cause a lot of manual effort. Be it for applications, information letters, practice visits, meter readings or returns processes. Thanks to its Deep-OCR, natif.ai form automation recognizes all text information, including handwriting. A wide variety of form types can be quickly created and automated. The software delivers real-time results, reduces manual effort, requires no setup costs and produces immediate savings. In addition, the entire process is easy and quick to integrate.
Plug & Play
Thanks to Rest API, our AI models are quickly integrated into existing systems.
Accuracy
Our AI models have been trained with hundreds of thousands of documents and extract all important information with high precision.
Speed
Thanks to high-performance GPUs, our AI processes documents in real time.
Languages
Our OCR supports various languages of the Latin alphabet.
Active learning
Automated processes are constantly improving the recognition rates of our technology.
Robust reading
Our Deep OCR reads even low-quality documents and can be specially adapted to difficult use cases.
Data protection
We are 100 % GDPR- and Schrems II-compliant. We process the data on our servers and dispense with service providers.
AI Boost
Our AI models directly enable your software to automate documents.
Einfach Integration dank Make-Plugin
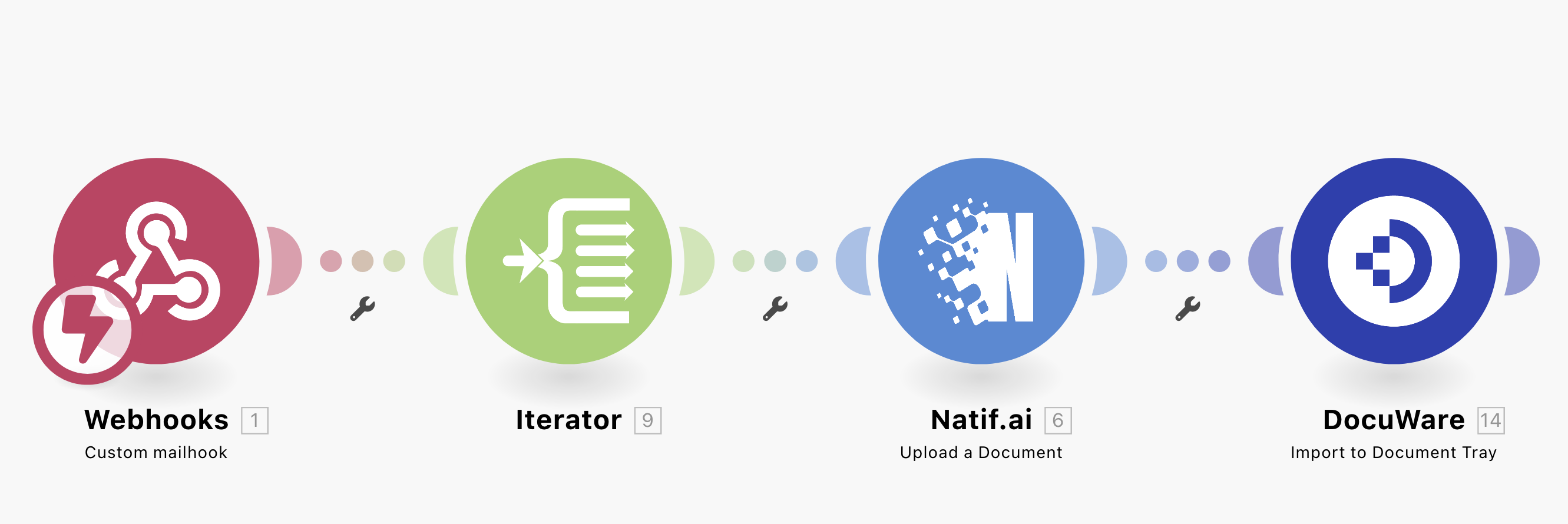
Easy integration thanks to Make-Plugin
Intuitive use of our technology and easy integration into existing processes such as in the DocuWare context thanks to our Make plugin.
Data extraction
We provide the key information as a structured JSON format via the API. For each data point, it also specifies the exact position on the document, the value and the confidence level. In addition to the JSON file, we provide a PDF/A file with the text level.
Ready for Automation?
Empower your workflow with intelligent document processing and discover our diverse AI solutions.
Contact us now to request your free demo!
Contact us now to request your free demo!
Ready for Automation?
Empower your workflow with intelligent document processing and discover our diverse AI solutions.
Contact us now to request your free demo!
Contact us now to request your free demo!