At natif.ai we work hard to provide an amazing generic invoice extraction model. The goal of this model is to be as good as possible on every invoice you can imagine, which is obviously a very hard goal to achieve.
However, we are aware that in your everyday life you are unlikely to receive every invoice, but are more likely to receive invoices from certain issuers over and over again, and from others less often. So amazing-generic may not be your ultimate goal, but rather perfection-for-your-issuers!
Many of our competitors try to achieve perfection by manually defining tailor-made rules to extract information from specific invoice templates. But what do you do when you occasionally receive invoices that don’t follow these templates? Should you create a new set of rules for every other invoice? Should you simply process such invoices manually?
Well, with natif.ai you don’t have to. Our amazing AI model can now be trained to be your perfect AI model! All it needs is a few minutes of your time and it will learn how to process your own invoices with impeccable precision.
In this post, we will walk you through our new API service that will enable you to fine-tune our amazing-generic invoice extraction model to be your perfect-specific invoice extraction model. And it all starts from our API Hub with the newly added “Train Invoice Extraction on your Data” service.
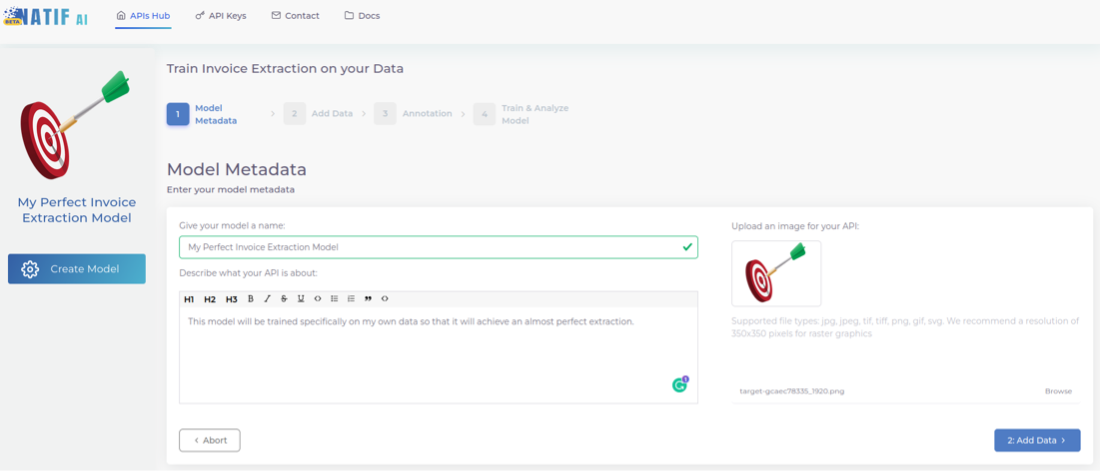
1. Give your model a personality
As usual, distinguish your model from the other APIs on your hub. You can specify the model’s name, a description and an image.
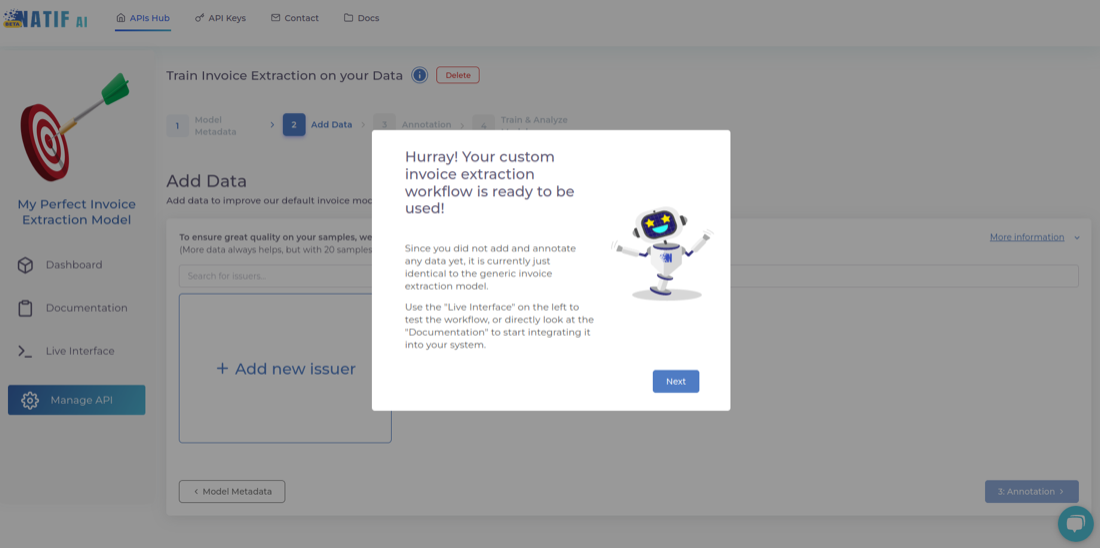
Once you have completed this step, you will be greeted with this message. This means that your AI model is initialised and fully usable. Initially it is a simple clone of the generic model, but in the next steps you can train it on your own data.
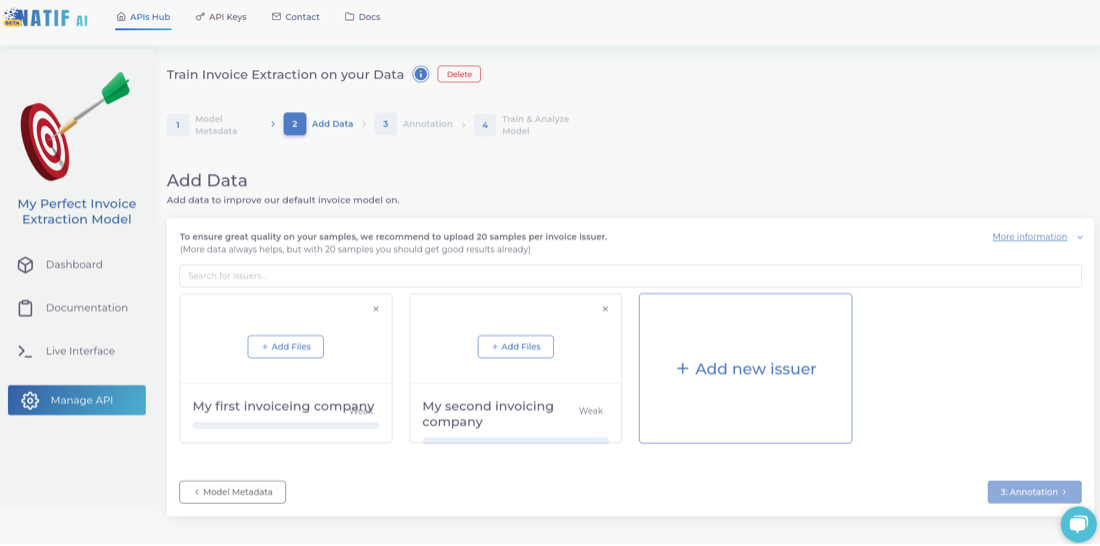
2. Add your data
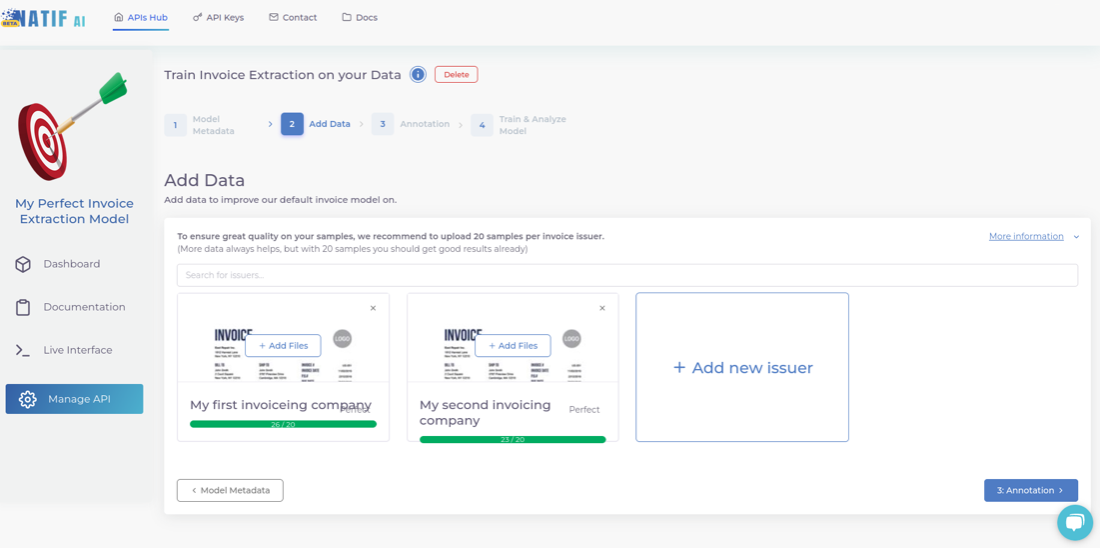
You are now ready to upload your own data for annotation. For the highest accuracy, we recommend that you upload your data issuer by issuer, so that you can annotate all samples of a particular template, one after the other, for consistency. Also, uploading issuer by issuer will allow you to later obtain issuer specific metrics so you can investigate what works well and what does not, which in turn will help you to further optimise your invoice model.
Of course, you don’t have to use this functionality, you can simply create an ‘unknown’ issuer and upload files from different issuers to it.
Once you have specified an issuer, start uploading data to each folder. Make sure you upload enough data for the model to learn properly.
3. Annotate your invoices
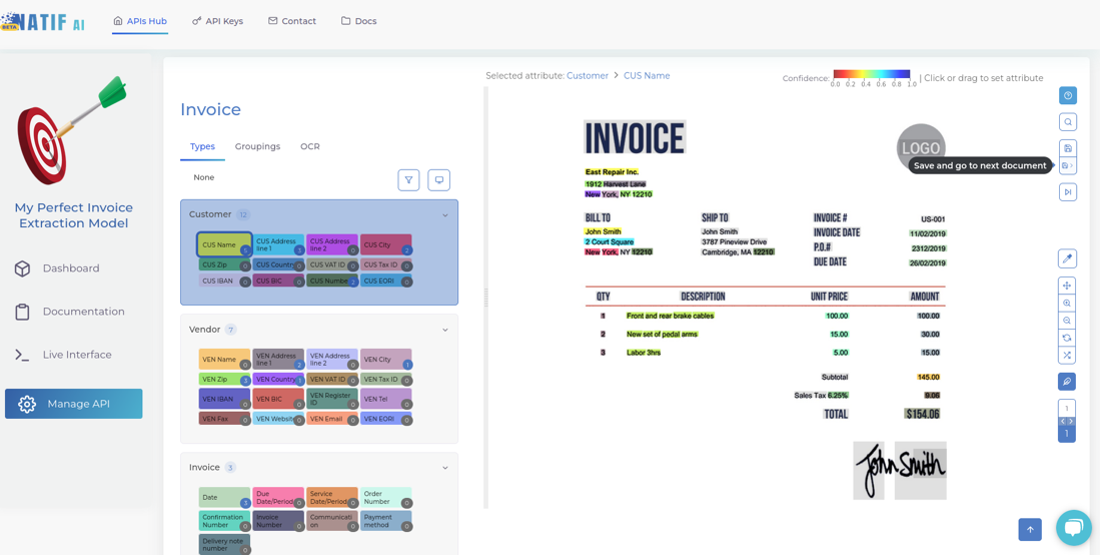
Pre-annotations are provided for each file. These annotations come from the generic model. So all you need to do is correct any small errors that may be present in each file.
If you find a text box with the wrong label or no label at all, simply select the label you want on the left and then click on the word on right. You will see its color change to the color of the label.
Also make sure that you group text fields that belong together correctly, e.g. line items or an IBAN together with its BIC.
When you are finished with the file, click ‘Save and go to next document’. We will display the invoices from a particular issuer first before moving on to the next issuer. This helps you to be consistent with your annotations and minimises the potential for annotation errors when moving between different templates.
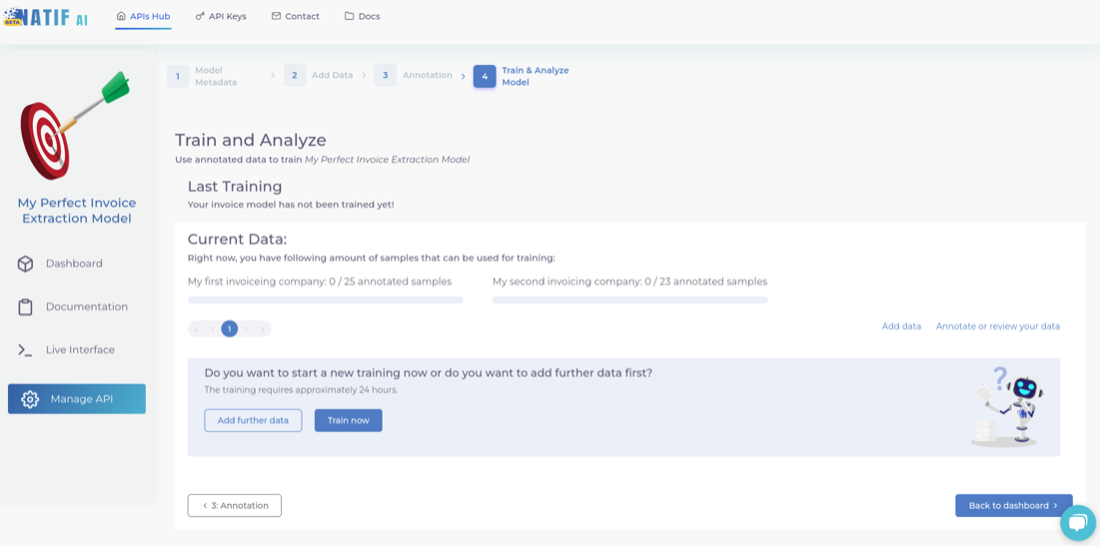
4. Train your model
Now you just need to press that “train now” button and wait for the model to finish training.
5. Analyse your model
Once training is finished, you can review the model’s performance and analyse which entities the model handled well and which it struggled with. You can then add more data or revise your annotations to help the model improve.
Voila! That’s how you can optimise our generic model for your own data, while still enjoying its great performance on any other invoices that might occasionally show up!