Poorly defined data fields can lead to inaccurate extraction results – especially when dealing with numbers, date formats, or complex hierarchies. Even within the same field type, small differences in structure can cause big issues.
Our Smart Field Configuration solves this problem by giving you full control: define numbers, date formats, and line items structures exactly the way you need.
In this tutorial, we’ll show you how to use Field Configuration to eliminate ambiguity in Data Extraction and ensure your custom extraction model delivers precise, reliable results.
Your Benefits With Smart Field Configuration
Our new Smart Field Configuration Feature makes defining and managing data fields easier than ever. With extensive data field explanations, you gain a deeper understanding of each field’s purpose and functionality.
More Precise Data Extraction: Define each data field according to your exact requirements and optimize extraction for maximum accuracy.
Maximum Flexibility: Even within the same field type, you can set individual formats and specific configurations.
Faster Setup: Thanks to detailed explanations and an optimized user interface, you save time and reduce errors.
More Efficient Workflows: The intuitive design and simplified creation process ensure seamless integration into your workflow.
Extended configuration settings allow for precise adjustments to meet your specific needs, while the simplified creation process ensures a more efficient workflow. These enhancements help you achieve greater accuracy and flexibility in your extraction models.
Optional Numbers Settings
With the Fallback Decimal Separator you can now determine how numbers with separators are interpreted when they are ambiguous – whether they should be treated as decimal numbers or thousands. There is no universal standard worldwide.
You can currently choose between these two formats:
– Comma (,) → Used in many European countries (e.g., 3,14)
– Dot (.) → Common in English-speaking countries (e.g., 3.14)
Note: If at least one number with separators is clearly present in your documents, we will learn from it and correctly interpret ambiguous numbers as well.
In this case, the number 1,000.50 appeared on one page. Based on the previous explanation, we know that the comma is used as a thousand separator. We remember this pattern, meaning the number on the right is now unambiguous, even without additional settings (Memory Mechanism).
Adjusting Date Formats
The Priority Rule for Date Interpretation determines how the model interprets a date in cases of ambiguity. Since there is no universal standard for date formats worldwide, the system follows predefined rules to convert dates into a standardized form.
You can currently choose between these three formats:
– Day First (DD.MM.YYYY) → E.g., 25.04.2025
– Month First (MM/DD/YYYY) → E.g., 04/25/2025
– Year First (YYYY-MM-DD) → E.g., 2025-04-25
This date is a clear example. There is no 25th month, so this must be the day.
For numbers up to 12, interpretation can be challenging:
It’s unclear whether they represent the day or the month. This creates ambiguity. For example, with „03/12/2025″, is it December 3rd or March 12th? To address such ambiguous cases, you can explicitly specify the Fallback Date Format for your documents to ensure accurate interpretation.
Note: If at least one date is clear on your documents, we will learn from it and correctly interpret ambiguous dates as well.
In this case, the unambiguous date 25/04/2025 appeared on a document.
This clarity is recognized, and the system learns that dates typically start with the day. It then applies this knowledge to ambiguous dates as well, even without additional settings (Memory Mechanism).
Define Hierarchical Line Items
Imagine you have a list where „Delivery Number 1020“ is written once, and below it, there are items like „Cement Bags,“ „Sand,“ and „Gravel.“ The problem is that the model doesn’t automatically know that these items belong to „Delivery 1020“ because the number isn’t repeated in each row.
The Hierarchical Items setting would be in this case:
– The Delivery Number applies to multiple items.
– It should be copied downward to each related item.
So instead of requiring the Delivery Number in every row, the model understands that everything under „Delivery 1020“ belongs to it – until a new Delivery Number appears, and the process starts over.
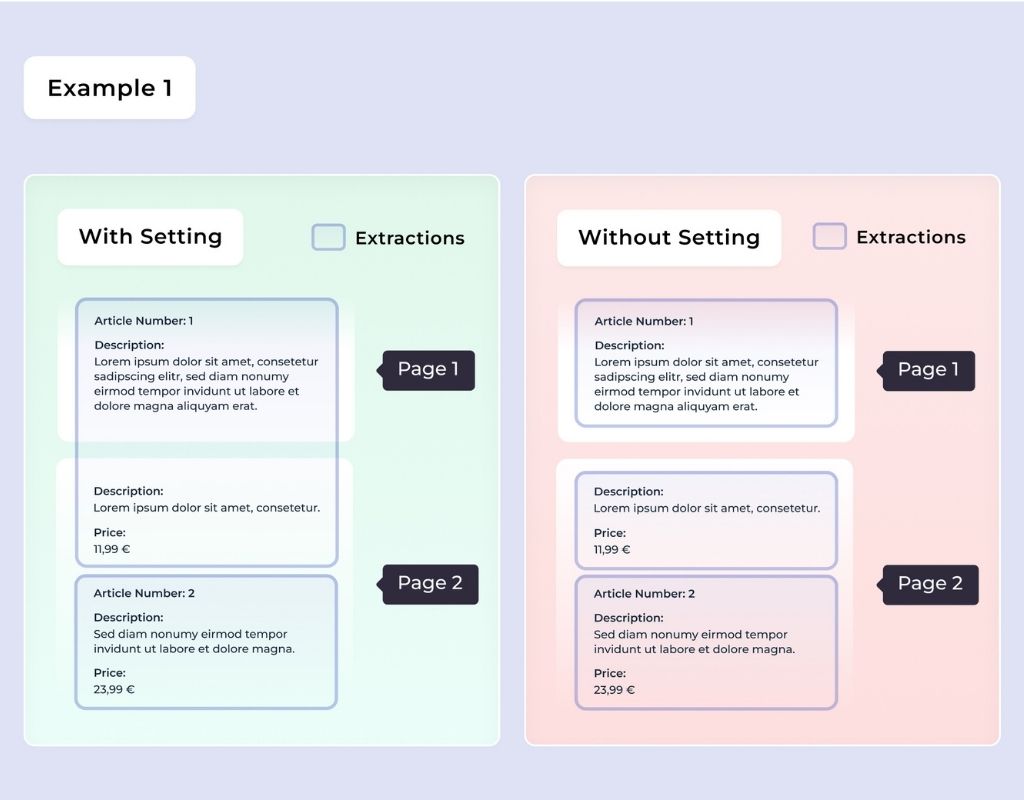
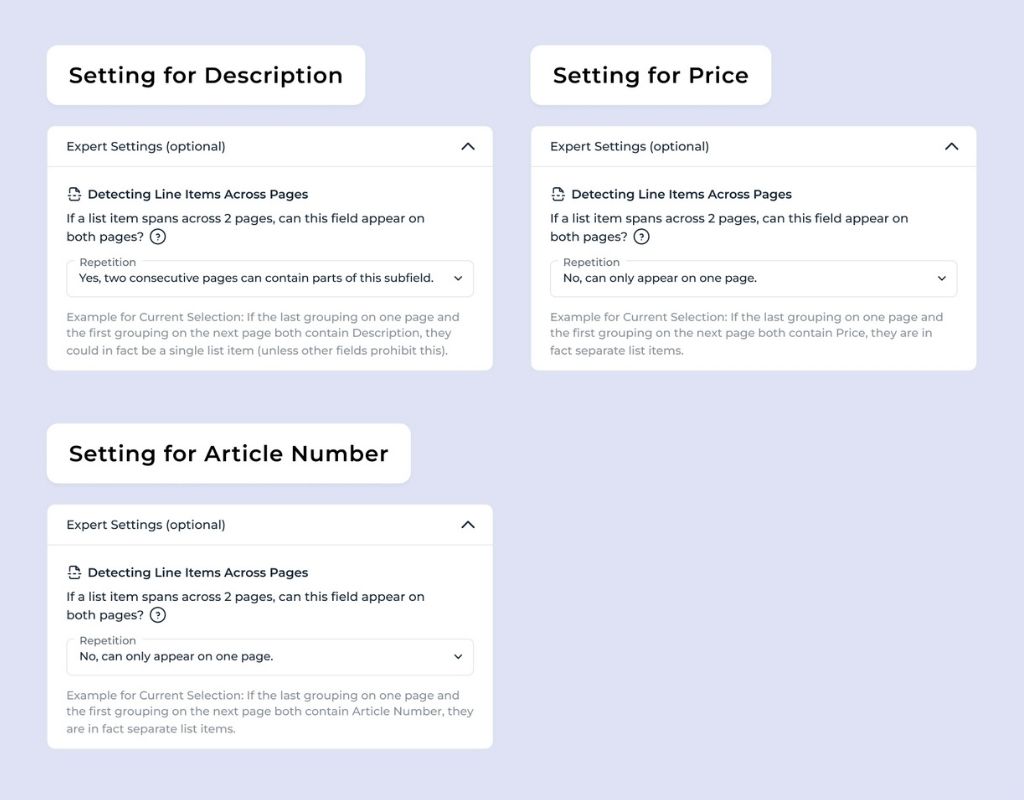
Detecting Line Items Across Pages
Imagine you have an item description that starts on page 1 and continues onto page 2. There is no automatic recognition that it’s the same item, so it is treated as two separate entries. This setting resolves the issue by using unique values — such as the article number or the price — to link related items together, as these values typically appear only once per list item.
The setting would be in this case:
– A Description can appear on multiple page
– A Price can not appear on multiple pages (unique value)
– An Article Number can not appear on multiple pages (unique values)
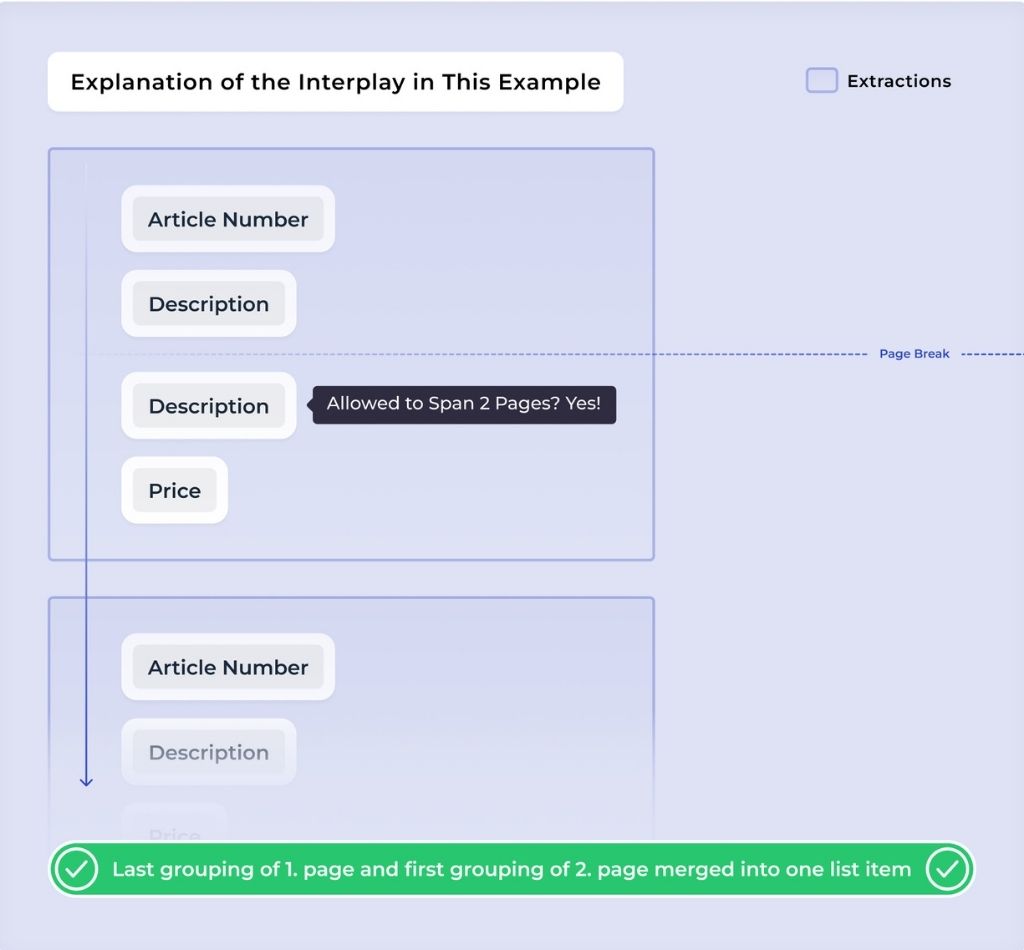
What’s important is that there’s always an interplay of multiple settings. In this case, the Description can span multiple pages as long as there’s no field that prohibits merging. We check whether the first entry on the next page contains anything that would block the merge. If not, the previous list item continues. A new item begins if the last grouping on one page and the first grouping on the next page both contain a value that can only appear on one page.
A second example below illustrates why the interplay between settings is so important. If we only consider the setting for price (allowed only once per item), the AI would merge the two line items — because the last list item on page 1 does not have a price. The AI would assume it’s a single item based on that single price occurrence.
However, the article number setting (also allowed only once per item) acts as a blocker. It interrupts the merge logic and helps the AI correctly recognize that these are two distinct items.


Without this setting, the second part on page 2 would be treated as another list element without an Article Number, containing only a description. Using a unique identifier ensures that content stays grouped correctly, even if it spans multiple pages.
Differences between pages:
Another scenario involves slight differences between pages. Example:
– Page 1 contains “Article Number” and “Description”
– Page 2 contains “Article Number”, “Description” and “Price”.
Although this looks like a continuation of the same list, the system treats it as two separate lists because the “Article Number” appears again on page 2 and is configured as a unique identifier.
In such cases, the entries would only be merged if the logic allowed repetition of certain fields (e.g. “Price”), while still treating “Article Number” as the primary anchor.
This highlights the importance of how different field settings interact when identifying list continuity across pages.
Create Your Custom Model Now
Our new Smart Field Configuration empowers you to create your perfect extraction models with ease. With more flexibility and control, you can tailor data fields to your specific needs and improve accuracy effortlessly.
Now it’s time to put these features into action – Start exploring the new feature today and create your custom extraction model to achieve even more precise and efficient results!