🚀 Discover natif.ai White Label! Use our innovative technology in your software and in your brand design.
About the importance of OCR quality and how to measure it
Almost all business processes involve documents at one point or another. To make the information actionable for automation, we need OCR, and we need it to be as good as possible.
Optical Character Recognition (OCR) is the process of converting images of documents or text into machine-readable text. OCR is not a new technology, but is currently experiencing massive demand due to the increasing automation of business processes in organizations. Almost all business processes involve documents at one point or another. To make the information actionable for automation, we need OCR, and we need it to be as good as possible.
The importance of OCR quality
To make the importance of OCR quality tangible, let’s look at more advanced automation tasks, such as Document Classification and Key Information Extraction.
Document classification:
Frequently, incoming documents are read with OCR and then classified in order to make them accessible to the right employees or to direct them to the right processes. The demands on the quality of the classification are high, but how can something be sent to the right employee if it has already not been read correctly? In other words, how can my documents be classified if the underlying OCR does not read them correctly?
Key information extraction:
Similarly, documents are often read with OCR to extract key information from the documents, to automatically feed processes with explicit information, or simply to save employees from tedious retyping. How can an algorithm, with fewer errors than a human, extract information from documents if the underlying text has not been read correctly?
Conclusion
OCR quality sets the natural upper bound for automation rates of document processes.
Although we have just seen how important the topic is, there are only a handful of real OCR engine providers on the market. Why “real”? Often OCR is purchased as a technology and offered as a white label solution. The technology providers behind it are often the same. To name the most well-known on the market:
To measure the quality of these providers we need a validation dataset (Ground Truth) that contains document pages with picture perfect OCR results and a suitable metric that indicates how high the quality is or, conversely, how low the error rate is compared to the validation set.
The terms character error rate (CER) or word error rate(WER) immediately come to mind. These metrics measure what percentage of characters/words in a given text are incorrect. Both metrics are quite similar, with the word error rate penalizing small errors more than the character error rate, since a single error with one letter already makes a whole word wrong. A good article about the metrics is by Kenneth Leung.
The two metrics are great for plain text. However, documents are text with a layout. The two metrics completely ignore where text was read and how wide or high the text is written at the corresponding position. In addition, it’s often hard to turn an entire document page into plain text so that you could apply CER or WHO. The reading order from left to right and top to bottom does not always make sense and is implemented differently from OCR engine to OCR engine — therefore a comparison only with CER or WER cannot be done.
Fortunately, all OCR engines have one thing in common: besides pure text, they also deliver bounding boxes on word level with position coordinates and the word contained in them.
A nice metrics that integrates a matching of layout based on word level bounding boxes is provided in the keras-ocr Github repository:
“Precision and recall were computed based on an intersection over union of 50% or higher and a text similarity to ground truth of 50% or higher.” — keras-ocr maintainer
Intersection over union (IoU) handles the position of the text and the text similarity is measured with CER. So, basically every single text box where the IoU to a given Ground Truth sample is higher then 50% and the CER is less then 50% compared to the Ground Truth is considered to be a match. Yes, it’s true this metrics is a very rough abstraction but tends to be a useful indication as we will see in the evaluation.
Now let’s look at an example where the above metric clearly fails. The following image shows the potential output of an OCR engine in line 1) and the bounding boxes of the ground truth example in line 2). Both outputs look fine, while the output in the second line is more fine-grained. The metrics presented above would probably penalize the output of the OCR engine with a 0% match.
Different ways to define word level bounding boxes
The problem that becomes apparent here is simply that it is not always clear how word-level bounding boxes should be created. Separating or joining text components is penalized too much by rigid metrics, although it is more a matter of taste.
Fortunately, a few clever minds have already given some thought to this very problem and presented a solution in Metrics for Complete Evaluation of OCR Performance. A procedure is proposed which allows matching of word-level bounding boxes; does not penalize word-level splits and merges; makes CER and WER applicable to the contents of the boxes. The underlying algorithm is called ZoneMapAltCnt.
We define the ZoneMapAltCnt metric […] and show that it offers the most reliable and complete evaluation […]
ZoneMapAltCnt first matches bounding boxes between the OCR output and the ground truth using the link force between the boxes. It is based on their mutual coverage rates; basically, the larger the intersection area between two boxes, the larger the link force. As the algorithm keeps track of the number of the resulting links, it is made explicit if the OCR engine performed word-level splits and merges.
This then allows a fine-grained approach to calculating CER and WER. If the OCR engine performed a split, ZoneMapAltCnt compares the ground truth with the concatenation of the split text to determine metrics for the given area. If the OCR engine performed a merge, the algorithm compares the concatenation of the resp. ground truth words with the OCR output. That way, ZoneMapAltCnt provides a meaningful way to measure OCR quality even if the engine makes different word-level splitting and merging decisions than the ground truth.
Evaluation
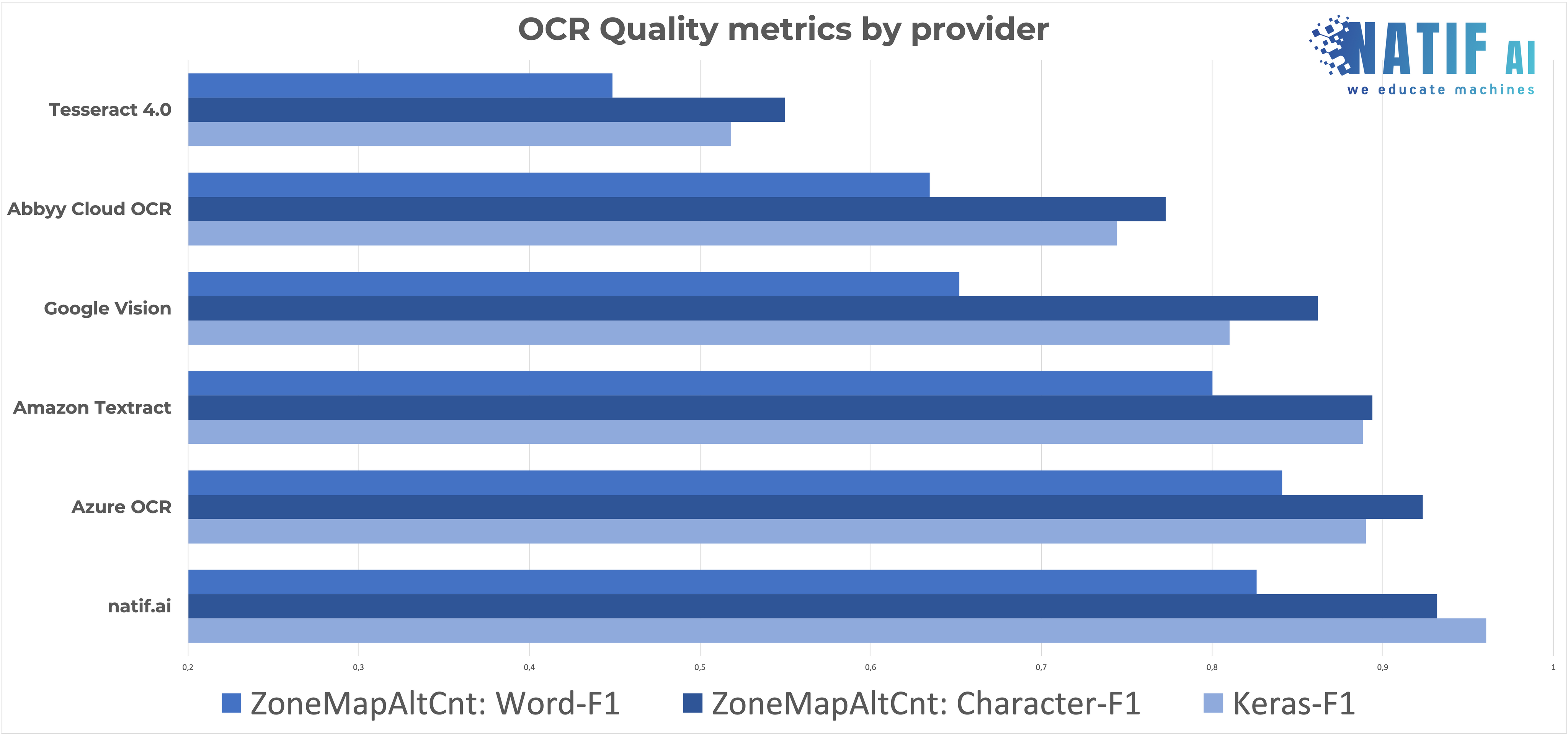
If you want to conduct your own experiments and implementation of the metric will soon be found on GitHub. For now, we ran ZoneMapScoreAlt with WER and CER, as well as the introduced keras-ocr metric on a dataset of ~100 document pages and show the results.
The evaluation shows that among the hyperscalers Amazon, Google and Microsoft, Microsoft clearly offers the best solution for OCR. The top dog Abbyy, which is known for its OCR technology, performs relatively poorly, but is still ahead of the open source alternative Tesseract. The best quality across all metrics is shown by natif.ai Platform , probably the least known provider. In honor of OpenSource, it should perhaps be mentioned that Tesseract can be further improved through targeted training. This feature is also offered by natif.ai on our online platform.
Data protection
It has nothing to do with OCR quality, but is probably a big influencing factor for many European companies looking for the best OCR solution — GDPR.
Abbyy, Tesseract and natif.ai can be installed on-premise and are therefore not a problem. The cloud variant of Abbyy, as well as the solutions of the hyperscalers, are not without risk, at least as far as Schrems II is concerned. Our Platform is the only one to offer a GDPR and Schrems II compliant OCR solution even in the cloud.