Die Bedeutung von OCR-Qualität und wie man sie misst
Nahezu alle Geschäftsprozesse beinhalten an der einen oder anderen Stelle Dokumente. Um die Informationen für die Automatisierung nutzbar zu machen, brauchen wir OCR – und zwar so gut wie möglich.
Unter Optical Character Recognition (OCR) versteht man die Umwandlung von Bildern von Dokumenten oder Texten in maschinenlesbaren Text. OCR ist keine neue Technologie, erfährt aber aufgrund der zunehmenden Automatisierung von Geschäftsprozessen in Unternehmen derzeit eine massive Nachfrage. Nahezu alle Geschäftsprozesse beinhalten an der einen oder anderen Stelle Dokumente. Um die Informationen für die Automatisierung nutzbar zu machen, brauchen wir OCR – und zwar so gut wie möglich.
Die Bedeutung von OCR-Qualität
Um die Bedeutung der OCR-Qualität greifbar zu machen, betrachten wir fortgeschrittenere Automatisierungsaufgaben wie die Klassifizierung von Dokumenten und die Extraktion von Schlüsselinformationen.
Klassifizierung von Dokumenten:
Häufig werden eingehende Dokumente mit OCR gelesen und anschließend klassifiziert, um sie den richtigen Mitarbeiter*innen zugänglich zu machen oder sie den richtigen Prozessen zuzuordnen. Die Anforderungen an die Qualität der Klassifizierung sind hoch, aber wie kann etwas an die richtige Person geschickt werden, wenn es schon nicht richtig gelesen wurde? Mit anderen Worten: Wie können die Dokumente klassifiziert werden, wenn die zugrunde liegende OCR sie nicht richtig liest?
Extraktion von Schlüsselinformationen:
Ebenso werden Dokumente oft mit OCR gelesen, um wichtige Informationen aus den Dokumenten zu extrahieren, damit Prozesse automatisch mit eindeutigen Informationen versorgt werden können oder einfach, um den Mitarbeiter*innen das mühsame Abtippen zu ersparen. Wie kann aber ein Algorithmus, der weniger Fehler macht als ein Mensch, Informationen aus Dokumenten extrahieren, wenn der zugrunde liegende Text nicht richtig gelesen wurde?
Fazit
Die OCR-Qualität setzt die natürliche Obergrenze für den Automatisierungsgrad von Dokumentenprozessen.
Obwohl gerade klar wurde, wie wichtig das Thema ist, gibt es nur eine Handvoll echter OCR-Engine-Anbieter auf dem Markt. Warum „echt“? Oft wird OCR als Technologie eingekauft und als White-Label-Lösung angeboten. Die dahinter stehenden Technologieanbieter sind oft dieselben. Die bekanntesten auf dem Markt sind folgende:
Um die Qualität dieser Anbieter zu messen, benötigen wir einen Validierungsdatensatz (Ground Truth), der Dokumentenseiten mit perfekten OCR-Ergebnissen enthält, und eine geeignete Metrik, die angibt, wie hoch die Qualität ist oder umgekehrt, wie niedrig die Fehlerrate im Vergleich zum Validierungssatz ist.
Dafür kommen einem die Zeichenfehlerrate (character error rate CER) oder Wortfehlerrate (word error rate WER) sofort in den Sinn. Sie messen, wie viel Prozent der Zeichen/Wörter in einem bestimmten Text falsch sind. Beide Metriken sind recht ähnlich, wobei die Wortfehlerrate kleine Fehler stärker bestraft als die Zeichenfehlerrate, da ein einziger Fehler mit einem Buchstaben bereits ein ganzes Wort falsch macht. Kenneth Leung hat einen guten Artikel über diese Metriken verfasst.
Die beiden Metriken eignen sich hervorragend für schlichte Texte. Die meisten Dokumente beinhalten jedoch Text mit einem Layout. Beiden Metriken beachten nicht, wo genau der Text gelesen wurde und wie breit oder hoch der Text an der entsprechenden Stelle geschrieben ist. Zusätzlich ist es oft schwierig, eine ganze Dokumentseite in reinen Text umzuwandeln, damit man CER oder WHO anwenden kann. Die Lesereihenfolge von links nach rechts und von oben nach unten ist nicht immer sinnvoll und wird von OCR-Engine zu OCR-Engine unterschiedlich umgesetzt – daher ist ein Vergleich nur mit CER oder WER nicht möglich.
Glücklicherweise haben alle OCR-Engines eines gemeinsam: Neben dem reinen Text liefern sie auch Bounding Boxes auf Wortebene mit Positionskoordinaten und dem darin enthaltenen Wort.
Eine gute Metrik, die einen Abgleich des Layouts auf der Basis von Bounding Boxes auf Wortebene integriert, wird im Github-Repository keras-ocr bereitgestellt:
“Precision und Recall wurden auf der Grundlage einer Schnittmenge über Union von mindestens 50% und einer Textähnlichkeit mit der Ground Truth von mindestens 50% berechnet.” — keras-ocr Maintainer
Intersection over Union (IoU) berücksichtigt die Position des Textes und die Übereinstimmung des Textes wird mit CER gemessen. Im Grunde genommen wird also jedes einzelne Textfeld, bei dem der IoU-Wert im Vergleich zu einem bestimmten Ground Truth-Beispiel höher als 50 % und der CER-Wert im Vergleich zum Ground Truth kleiner als 50 % ist, als Übereinstimmung betrachtet. Es stimmt zwar, dass diese Metrik eine sehr grobe Abstraktion ist, aber sie ist tendenziell ein nützlicher Indikator, wie man in der Auswertung sehen wird.
Betrachten wir nun ein Beispiel, bei dem die obige Metrik offensichtlich nicht funktioniert. Das folgende Bild zeigt in Zeile 1) die potenzielle Ausgabe einer OCR-Engine und in Zeile 2) die Bounding Boxes des Beispiels der Grundwahrheit. Beide Ausgaben sehen gut aus, während die Ausgabe in der zweiten Zeile feinkörniger ist. Die oben vorgestellten Metriken würden wahrscheinlich die Ausgabe der OCR-Engine mit einer 0%igen Übereinstimmung bewerten.
Verschiedene Möglichkeiten zur Definition von Bounding Boxes auf Wortebene
Das Problem, das hier deutlich wird, besteht einfach darin, dass nicht immer klar ist, wie Bounding Boxes auf Wortebene erstellt werden sollten. Das Trennen oder Verbinden von Textbestandteilen wird durch starre Metriken zu sehr benachteiligt, obwohl dies eher eine Frage des individuellen Geschmacks ist.
Glücklicherweise haben sich einige clevere Köpfe bereits Gedanken über genau dieses Problem gemacht und in Metrics for Complete Evaluation of OCR Performance eine Lösung vorgestellt. Es wird ein Verfahren vorgeschlagen, das den Abgleich von Bounding Boxes auf Wortebene ermöglicht, Splits und Merges auf Wortebene nicht bestraft und CER und WER auf den Inhalt der Boxen anwendbar macht. Der zugrunde liegende Algorithmus wird ZoneMapAltCnt genannt.
We define the ZoneMapAltCnt metric […] and show that it offers the most reliable and complete evaluation […]
ZoneMapAltCnt gleicht zunächst Bounding Boxes zwischen der OCR-Ausgabe und der Grundwahrheit unter Verwendung der Link Force zwischen den Boxes ab. Sie basiert auf den gegenseitigen Abdeckungsraten; je größer der Schnittbereich zwischen zwei Boxen ist, desto größer ist die Linkstärke. Da der Algorithmus die Anzahl der sich ergebenden Verknüpfungen verfolgt, ist es eindeutig, ob die OCR-Engine Splits und Merges auf Wortebene durchgeführt hat.
Dies ermöglicht dann einen feinkörnigen Ansatz zur Berechnung von CER und WER. Wenn die OCR-Engine eine Aufteilung vorgenommen hat, vergleicht ZoneMapAltCnt die Grundwahrheit mit der Verkettung des aufgeteilten Textes, um Metriken für den jeweiligen Bereich zu ermitteln. Wenn die OCR-Engine eine Zusammenführung durchgeführt hat, vergleicht der Algorithmus die Verkettung der jeweiligen Grundwahrheitswörter mit der OCR-Ausgabe. Auf diese Weise bietet ZoneMapAltCnt eine aussagekräftige Methode zur Messung der OCR-Qualität, selbst wenn die OCR-Engine auf Wortebene andere Aufteilungs- und Zusammenführungsentscheidungen trifft als die Grundwahrheit.
Messung
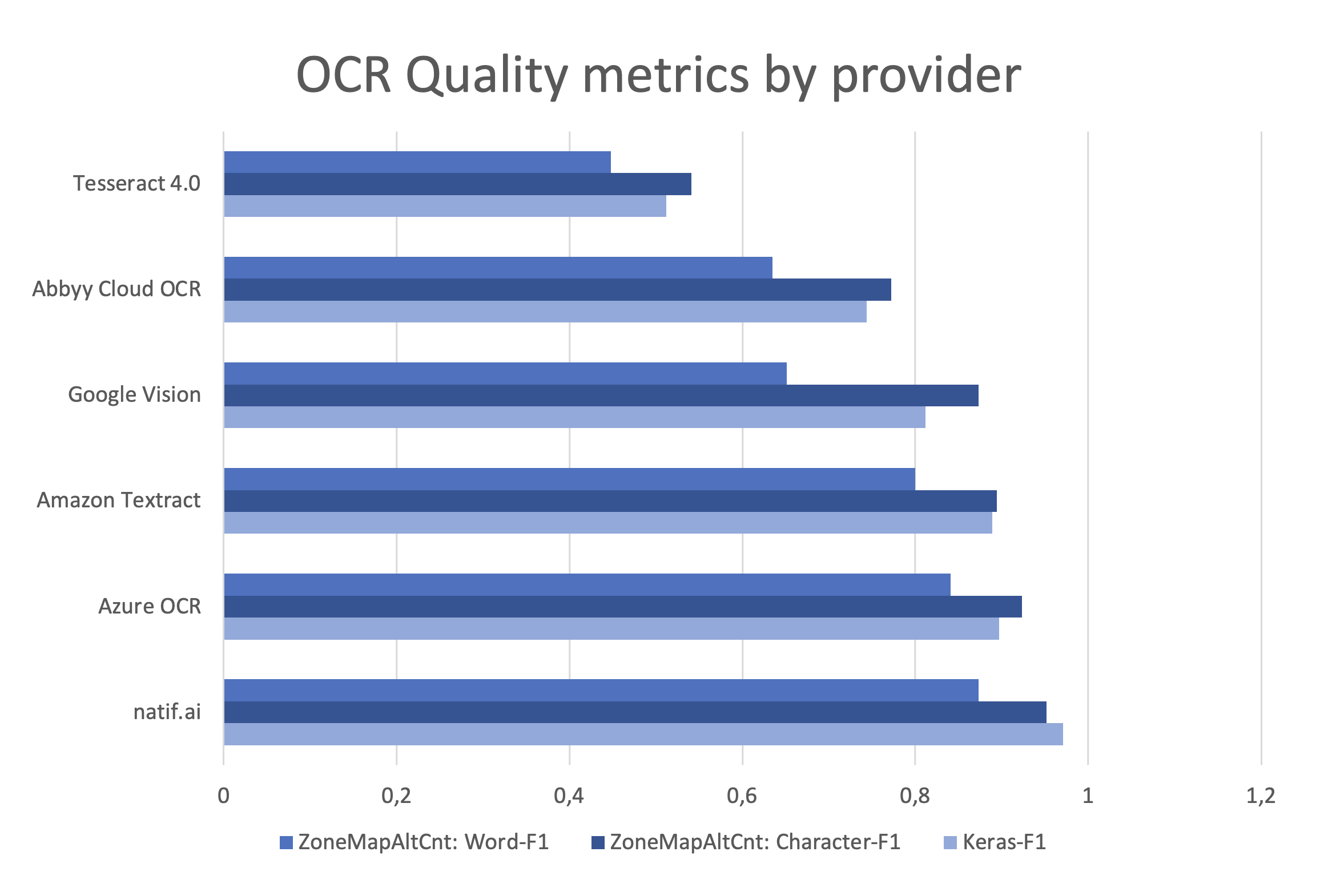
Wenn Sie Ihre eigenen Experimente und die Implementierung der Metrik durchführen möchten, finden Sie diese bald auf GitHub. Momentan haben wir ZoneMapScoreAlt mit WER und CER sowie der vorgestellten keras-ocr-Metrik auf einem Datensatz von ~100 Dokumentseiten ausgeführt und können folgende Ergebnisse betachten.
Die Auswertung zeigt, dass unter den Hyperscalern Amazon, Google und Microsoft letzterer eindeutig die beste Lösung für OCR bietet. Der Platzhirsch Abbyy, der für seine OCR-Technologie bekannt ist, schneidet relativ schlecht ab, liegt aber noch vor der Open-Source-Alternative Tesseract. Die beste Qualität über alle Metriken hinweg zeigt natif.ai Plattform, der wohl am wenigsten bekannte Anbieter.
Im Sinne von OpenSource sollte vielleicht noch erwähnt werden, dass Tesseract durch gezieltes Training weiter verbessert werden kann. Diese Funktion wird auch von natif.ai auf unserer Online-Plattform angeboten.
Datenschutz
Dies hat grundsätzlich nichts mit der OCR-Qualität zu tun, ist aber wahrscheinlich ein großer Einflussfaktor für viele europäische Unternehmen auf der Suche nach der besten OCR-Lösung – DSGVO.
Abbyy, Tesseract und Platform können On-Premise installiert werden und sind daher kein Problem. Die Cloud-Variante von Abbyy sowie die Lösungen der Hyperscaler sind, zumindest was Schrems II betrifft, nicht ohne Risiko. natif.ai ist das einzige Unternehmen, das eine DSGVO- und Schrems II-konforme OCR-Lösung auch in der Cloud anbietet.