Our vision at natif.ai is to have “A world without manual document tasks”. To fulfil this vision, we offer multiple models with the sole aim of helping you process your documents efficiently and reliably. We also provide models that you can customize and train on your own data if our pre-built models don’t fulfil your needs.
So far, all of our models expect single documents as input, i.e. PDFs/images containing only a single document. However, if your customers scan several documents in one go and send a long PDF containing all of them, this assumption is not fulfilled. Similarly, if you receive a lot of physical mail and want to digitize it, it is much easier to scan them all together rather than separately, but this makes them unusable for most subsequent automation processes. There are some techniques to help with this problem, such as labelling each document with a barcode that can be used later to automatically split the documents. However, this would still be a tedious task that you would have to do each time you receive physical documents, and that you would have to have your customers do when they send you documents, which is not really a viable solution.
Therefore, as a part of our vision, we want to help you get rid of the hassle of manually splitting documents by using our new document splitting model. This model will help you split a PDF file that contains multiple documents and download each document individually based on the semantic understanding of the content as well as the visual cues. All you need to do is to put them all in the scanner and send the scanned file to our document splitting model.
So, this post will walk you through our document splitting model to see how your scanned file is easily split.
1. Select our Generic Splitting Model
You can find the model on our
API-Hub where it is already trained and ready to be used uses.
The model page will include a description about the model as well as the documentation and your own usage.
2. Upload your file and check the results
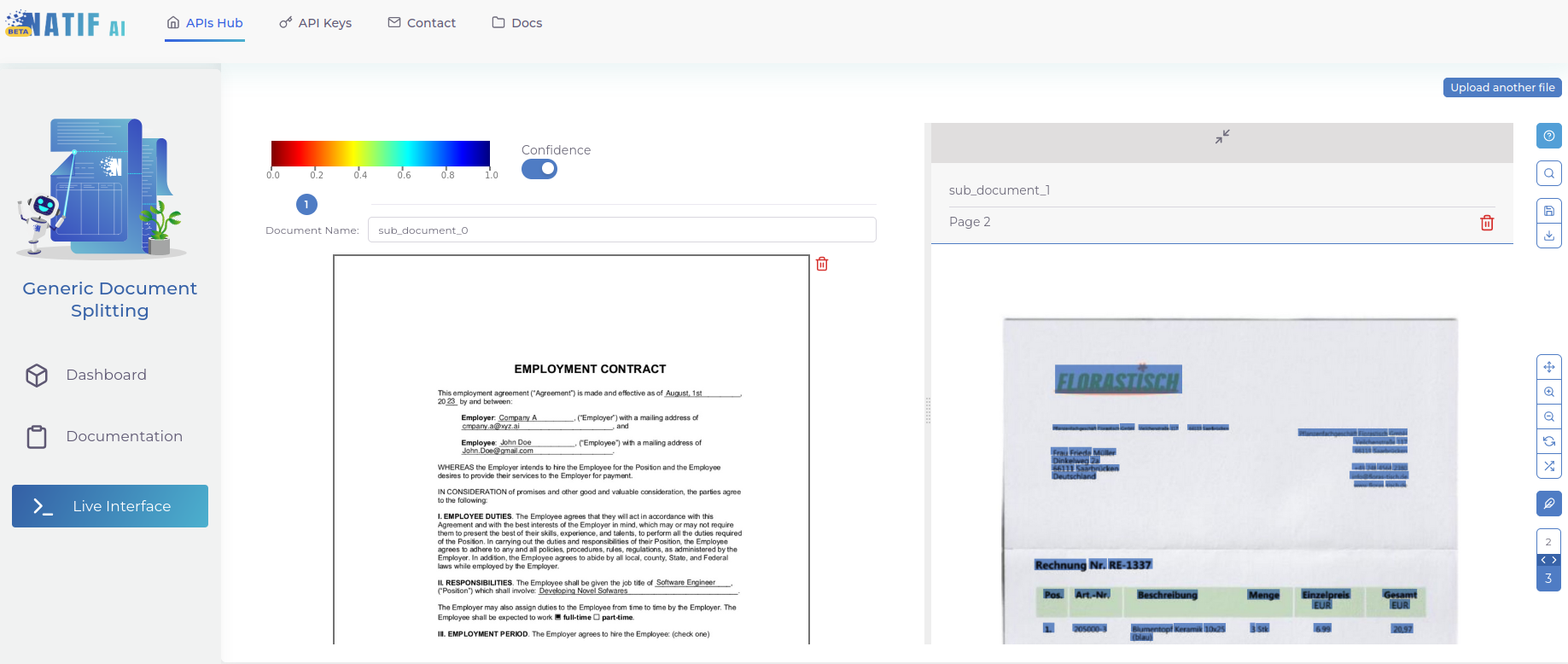
Go to the “Live Interface” and drag & drop a file to see the model’s predictions. It will show you the start page of such sub-PDF and allow you to download the individual files.
Voilà! That’s how easy splitting is with modern AI technology!
Go to the “Documentation” to see how you can achieve the same thing you just did in the interface with a single POST request, including code snippets, etc.
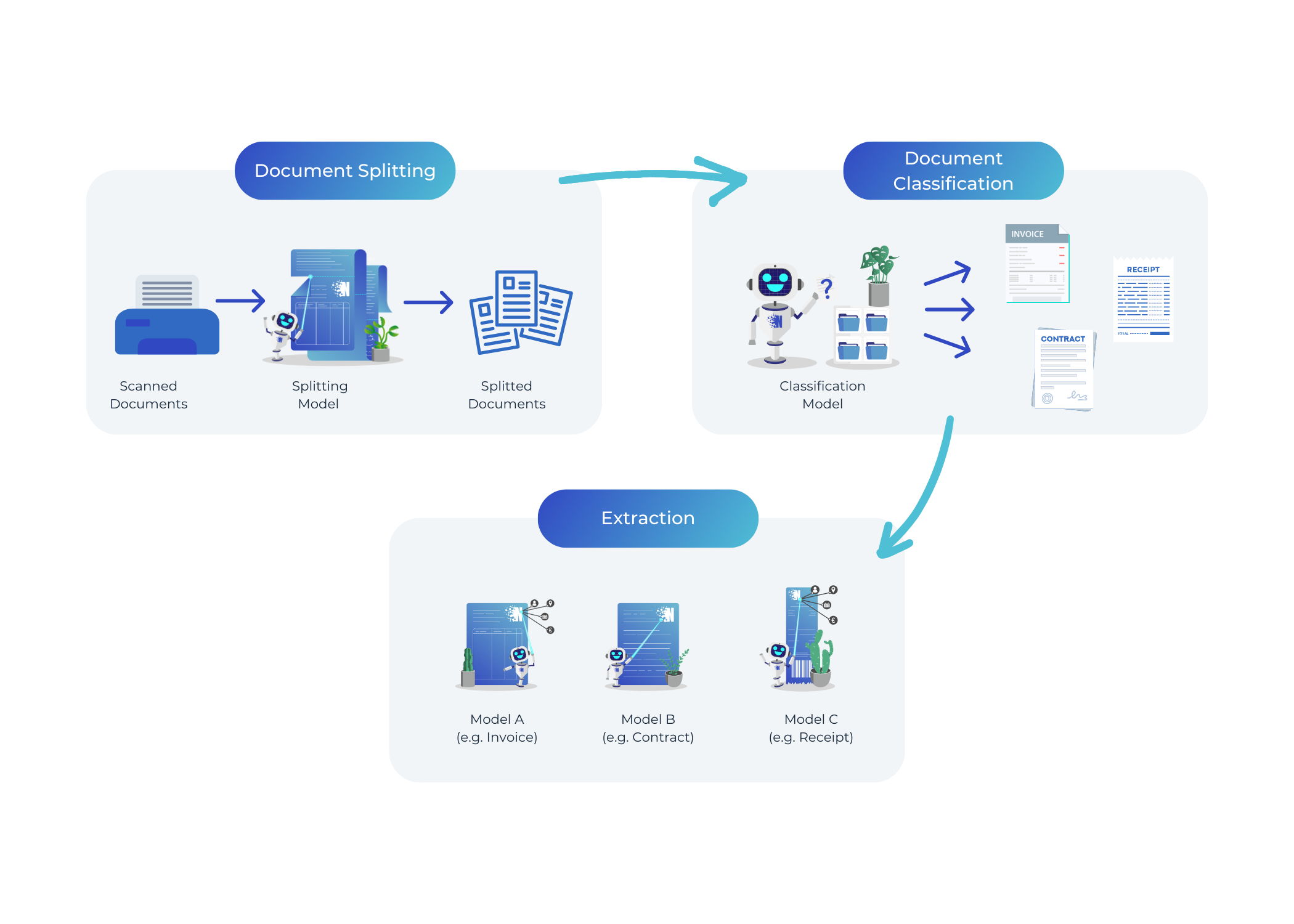
Even though splitting is a valuable step on its own, you don’t need to stop there.
You can also train a model that automatically sorts your files for you, as explained in this
blog. Moreover, you can
train your own extraction models to pull out all important information from your documents. And that’s how we give you a
fully integrated pipeline to automatically process your documents!