Unsere Vision bei natif.ai ist „eine Welt ohne manuelle Dokumentenaufgaben„.
Um diese Vision zu verwirklichen, haben wir mehrere Modelle entwickelt, deren einziges Ziel es ist, Sie bei der effizienten und zuverlässigen Verarbeitung Ihrer Dokumente zu unterstützen. Auch bieten wir die Möglichkeit an, eigene Modelle zu erstellen – falls unsere vorgefertigten Modelle nicht Ihren Anforderungen entsprechen.
Bisher gehen alle unsere Modelle von einzelnen Dokumenten aus, d.h. von PDFs/Bildern, die nur ein einziges Dokument enthalten.
Wenn Ihre Kunden jedoch mehrere Dokumente auf einmal scannen und eine lange PDF-Datei mit allen Dokumenten senden, ist diese Annahme nicht erfüllt. Ähnlich verhält es sich, wenn Sie eine Menge physischer Post erhalten und diese digitalisieren wollen. Es ist viel einfacher, sie alle zusammen zu scannen als einzeln, aber das macht sie für die meisten nachfolgenden Automatisierungsprozesse unbrauchbar.
Es gibt einige Möglichkeiten dieses Problem zu lösen, wie z. B. die Kennzeichnung jedes Dokuments mit einem Strichcode, der später zur automatischen Aufteilung der Dokumente verwendet werden kann. Das wäre jedoch eine mühsame Aufgabe, die Sie jedes Mal bei eingehender Post durchführen müssten. Auch müssten Ihre Kunden einen Strichcode anbringen, wenn sie Ihnen Dokumente schicken.
Eine wirklich praktische Lösung ist das also nicht.
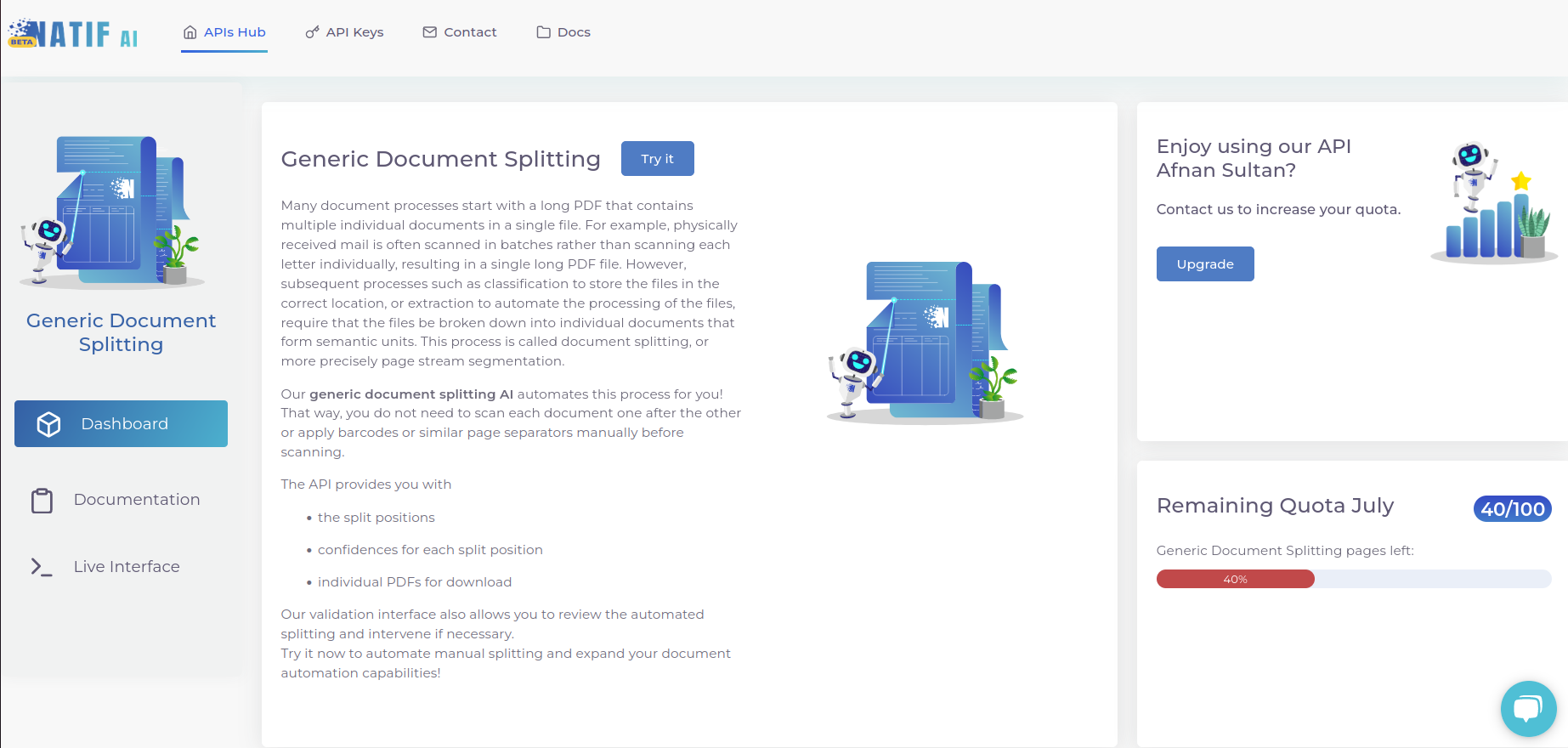
Deshalb möchten wir Ihnen mit unserem neuen Modell zur Dokumententrennung helfen, das mühsame manuelle Trennen von Dokumenten zu vermeiden. Dieses Modell hilft Ihnen, eine PDF-Datei, die mehrere Dokumente enthält, aufzuteilen und jedes Dokument einzeln herunterzuladen, basierend auf dem semantischen Verständnis des Inhalts und den visuellen Hinweisen.
Alles, was Sie tun müssen, ist, alle Dokumente in den Scanner zu legen und die gescannte Datei an unser Modell zu senden.
In diesem Beitrag werden wir Ihnen unser Document Splitting Model vorstellen und Ihnen zeigen, wie leicht Sie Ihre eingescannten Dokumente automatisiert wieder trennen können.
1. Wählen Sie unser generisches Splitting Model
Sie finden das Modell dann in unserem
API-Hub, wo es bereits trainiert ist und verwendet werden kann.
Auf der Seite des Modells finden Sie eine kurze Beschreibung, die Dokumentation und Ihre Usage.
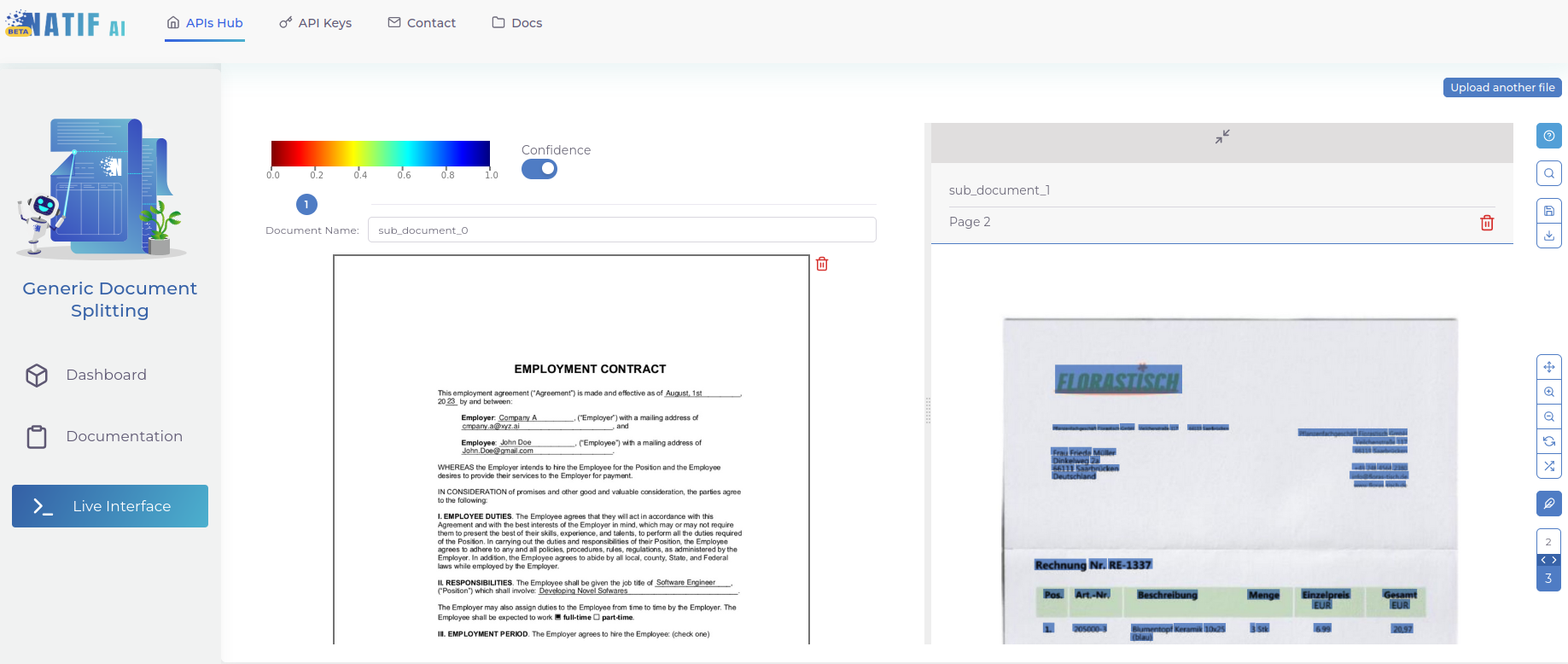
2. Laden Sie Ihre Datei hoch und checken Sie das Ergebnis
Gehen Sie zum „Live-Interface“ und laden Sie eine Datei per Drag & Drop hoch. Das Modell wird Ihnen dann die Startseite jedes einzelnen Dokuments anzeigen. Sie können die einzelnen Dateien noch benennen und anschließend als PDF herunterladen.
Voilà! So einfach ist Dokumententrennung mit moderner KI-Technologie!
In der Dokumentation sehen Sie, wie Sie das Modell mit einer einzigen POST-Anfrage integrieren können. Dort finden Sie alle notwendigen Informationen wie bspw. Code Snippets.
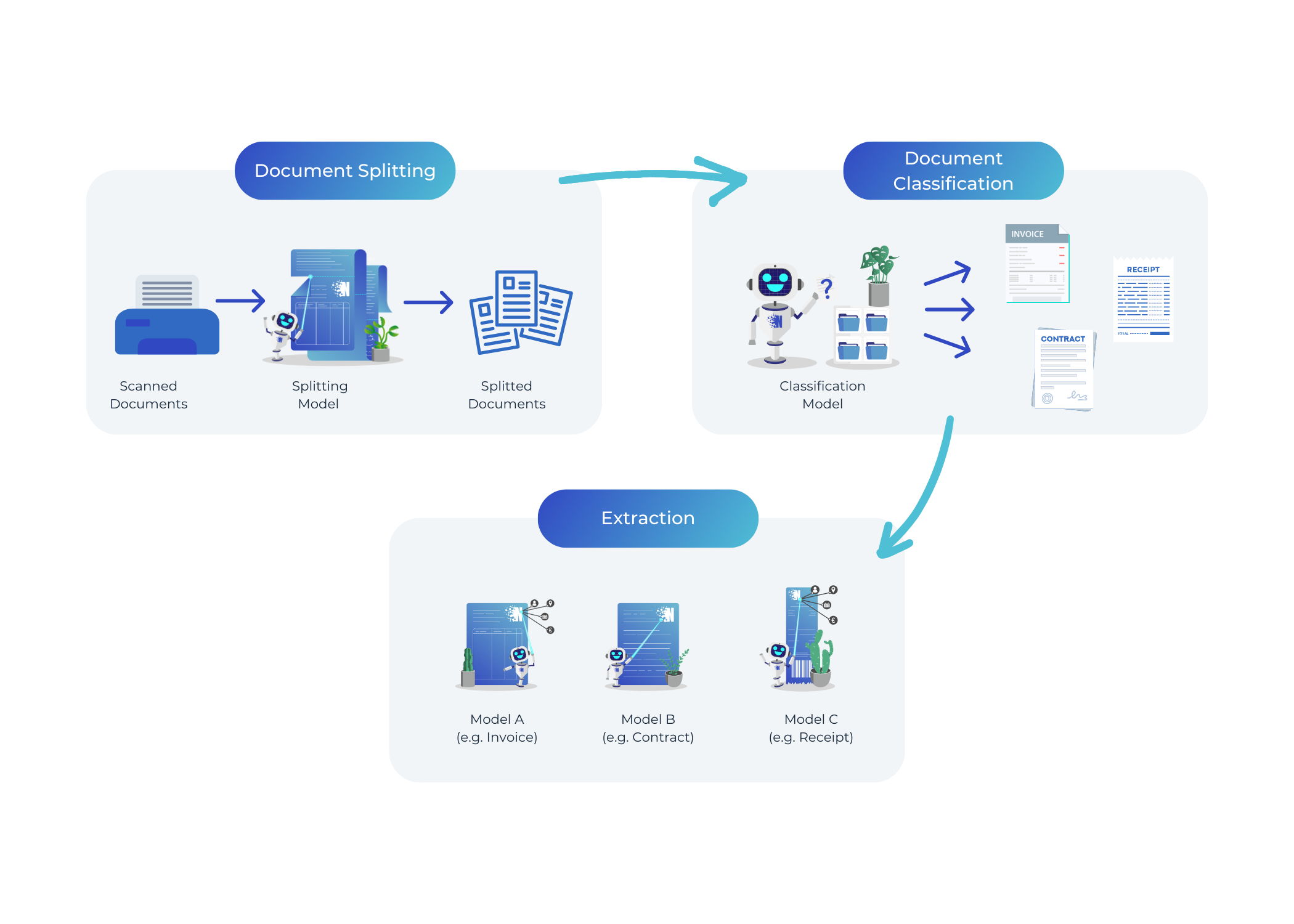
Auch wenn das Splitting an sich schon ein wertvoller Schritt ist, müssen Sie es nicht dabei belassen.
Sie können bspw. auch ein Modell trainieren, das Ihre Dateien automatisch für Sie sortiert, wie in diesem
Blog beschrieben. Außerdem können Sie Ihre
eigenen Extraktionsmodelle trainieren, um alle wichtigen Informationen aus Ihren Dokumenten zu extrahieren.
So bieten wir Ihnen eine vollständig integrierte Pipeline zur automatischen Verarbeitung Ihrer Dokumente!