Unsere Technologie verfügt über zahlreiche Modelle, die relevante Informationen aus Dokumenten wie Rechnungen, Quittungen, Fahrzeugscheinen und Lieferscheinen extrahieren. Für jede dieser Arten von Dokumenten extrahieren unsere Modelle die spezifischen Informationen, die für die weitere Verarbeitung benötigt werden, wie z. B. die Steuernummer, das Bankkonto usw.
Uns ist allerdings klar, dass Arbeitsprozesse nicht nur auf diese Dokumenttypen beschränkt sind und dass die Extraktion von Informationen aus anderen Dokumenten die Automatisierung vieler weiterer Geschäftsprozesse ermöglicht.
Anstatt also darauf zu warten, dass wir ein Modell für jeden Dokumententyp erstellen – das möglicherweise nicht alle gewünschten Felder enthält – können Sie es jetzt selbst in die Hand nehmen und Ihr eigenes Modell erstellen!
Mit unserem neuen
Wizard zur Erstellung von Extraktionsmodellen können Sie ein Modell erstellen, das die von Ihnen angegebenen Informationen aus den gewünschten Dokumenten extrahiert.
In diesem Beitrag führen wir Sie durch die Funktion und zeigen Ihnen, wie einfach die Extraktion von Informationen aus Ihren Dokumenten sein könnte!
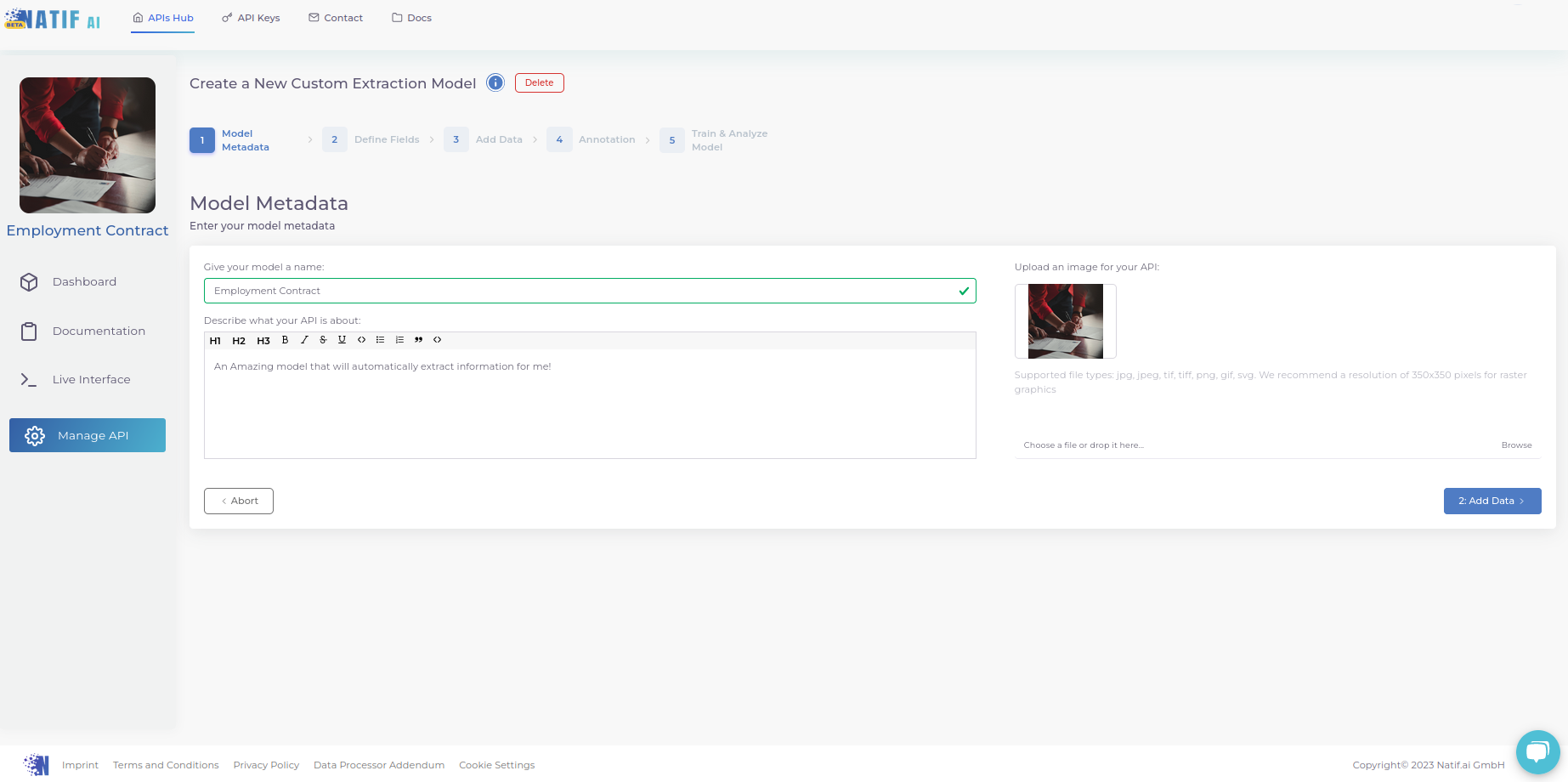
1. Geben Sie Ihrem Modell eine Persönlichkeit
Damit Sie Ihr Modell von den anderen APIs in Ihrem Hub unterscheiden können, haben Sie hier die Möglichkeit, einen Modellnamen, eine Beschreibung und ein Bild hinzuzufügen.
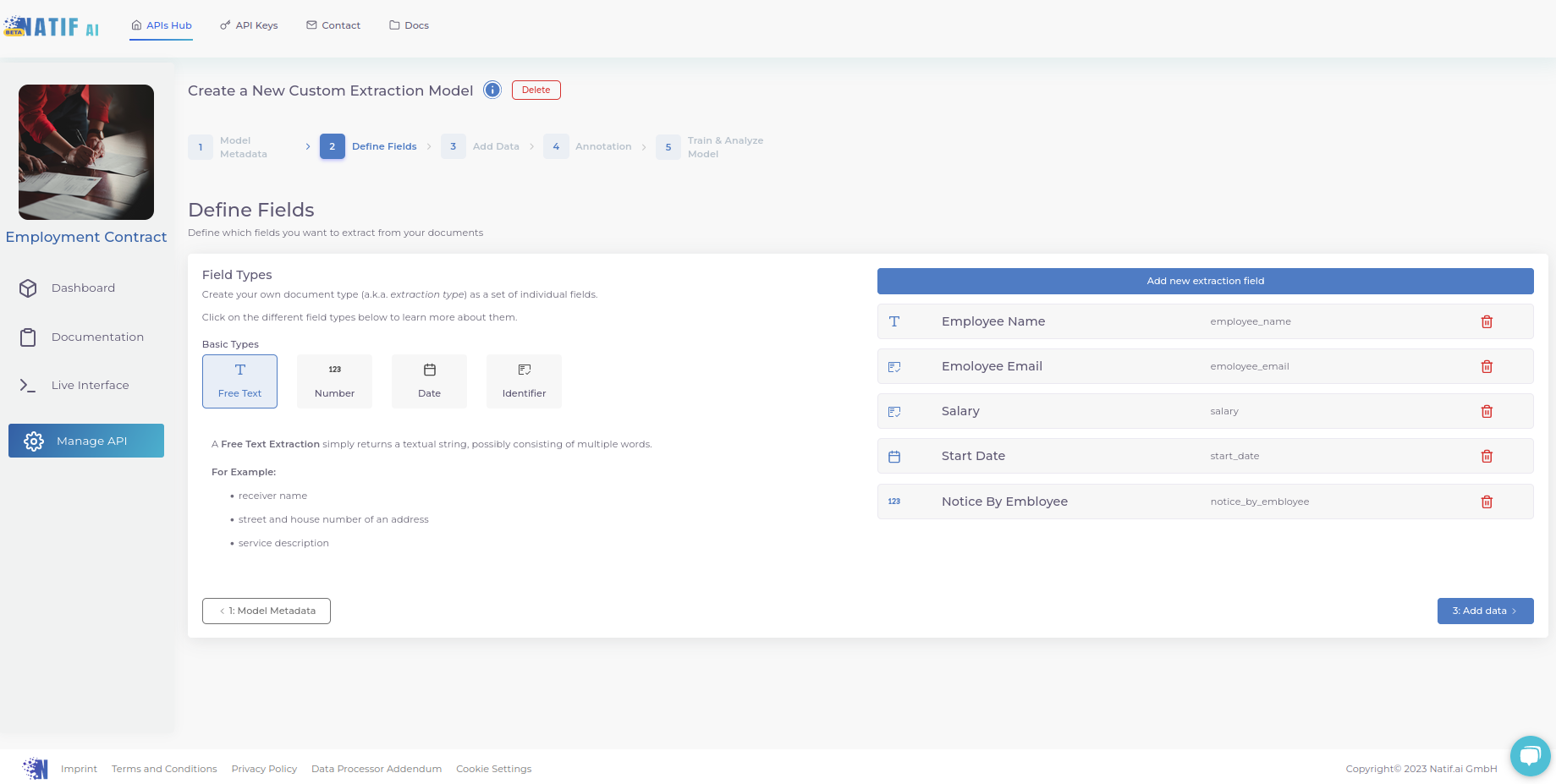
2. Bestimmen Sie die Extraktionsfelder
Teilen Sie dem Modell mit, welche Art von Informationen Sie extrahieren möchten.
Geben Sie jedem Feld einen Namen und geben Sie seinen Typ an (z. B. Text? Zahl? Datum? Kennung?). Die Bedeutung jedes Typs wird auf der linken Seite näher erläutert, wie im Screenshot zu sehen ist.
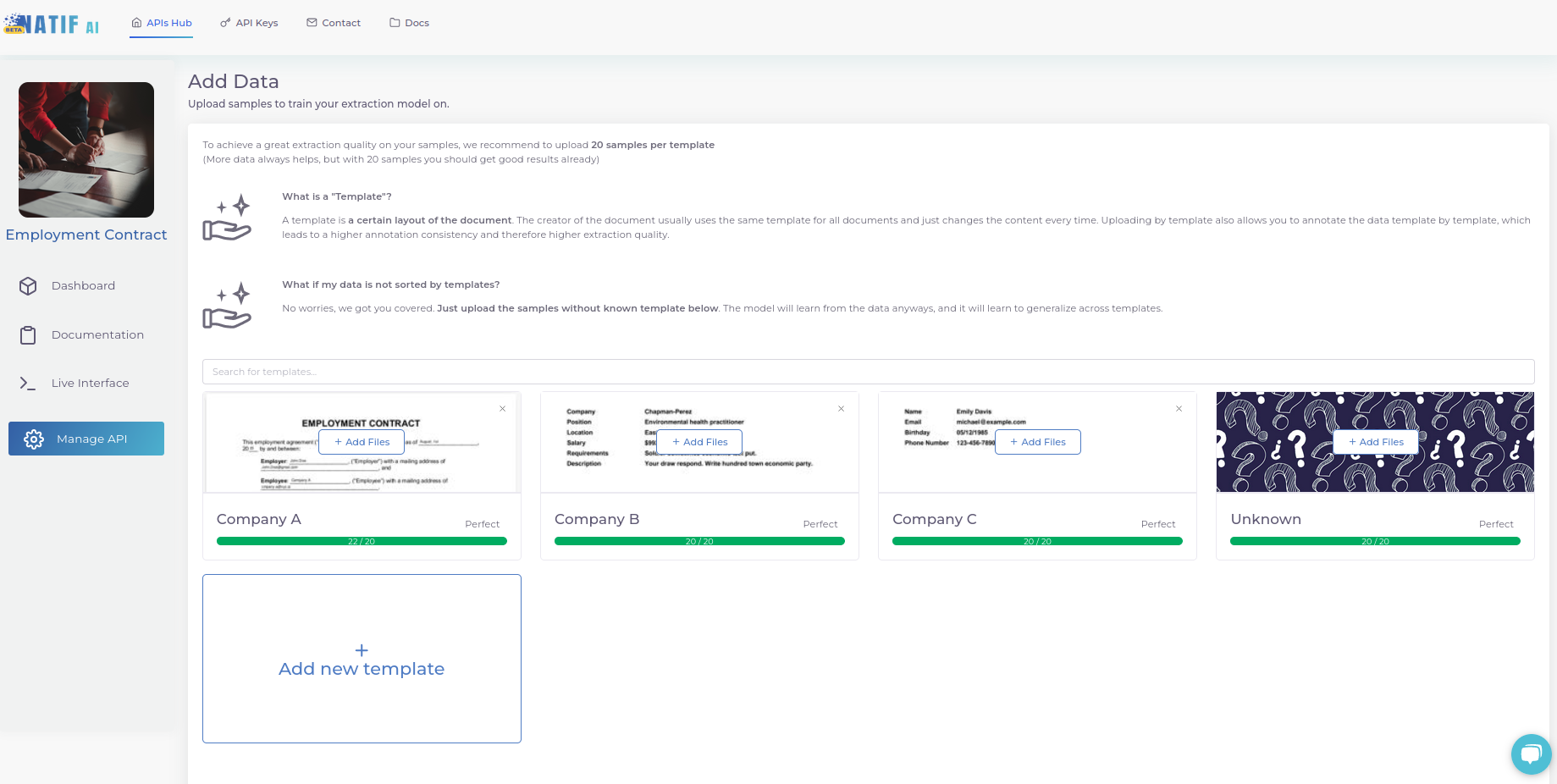
3. Laden Sie Ihre Dokumente hoch
Idealerweise laden Sie für jede Vorlage, die Sie regelmäßig erhalten, mehrere Dokumente hoch. Wenn Ihre Dokumente sehr unterschiedlich sind und jedes Mal anders aussehen, können Sie sie auch hochladen, ohne eine bekannte Vorlage zuzuweisen, und die KI lernt, alle Layouts zu verallgemeinern.
Wir empfehlen Ihnen, Ihre Dateien nach Dokumententyp sortiert hochzuladen. So können Sie anschließend Dokumententyp nach Dokumententyp annotieren und erhalten die größtmögliche Konsistenz. Achten Sie immer darauf, dass Sie genügend Dokumente hochladen, damit das Modell ausreichend lernen kann, insbesondere wenn Sie Beispiele die Angabe des Typs hochladen.
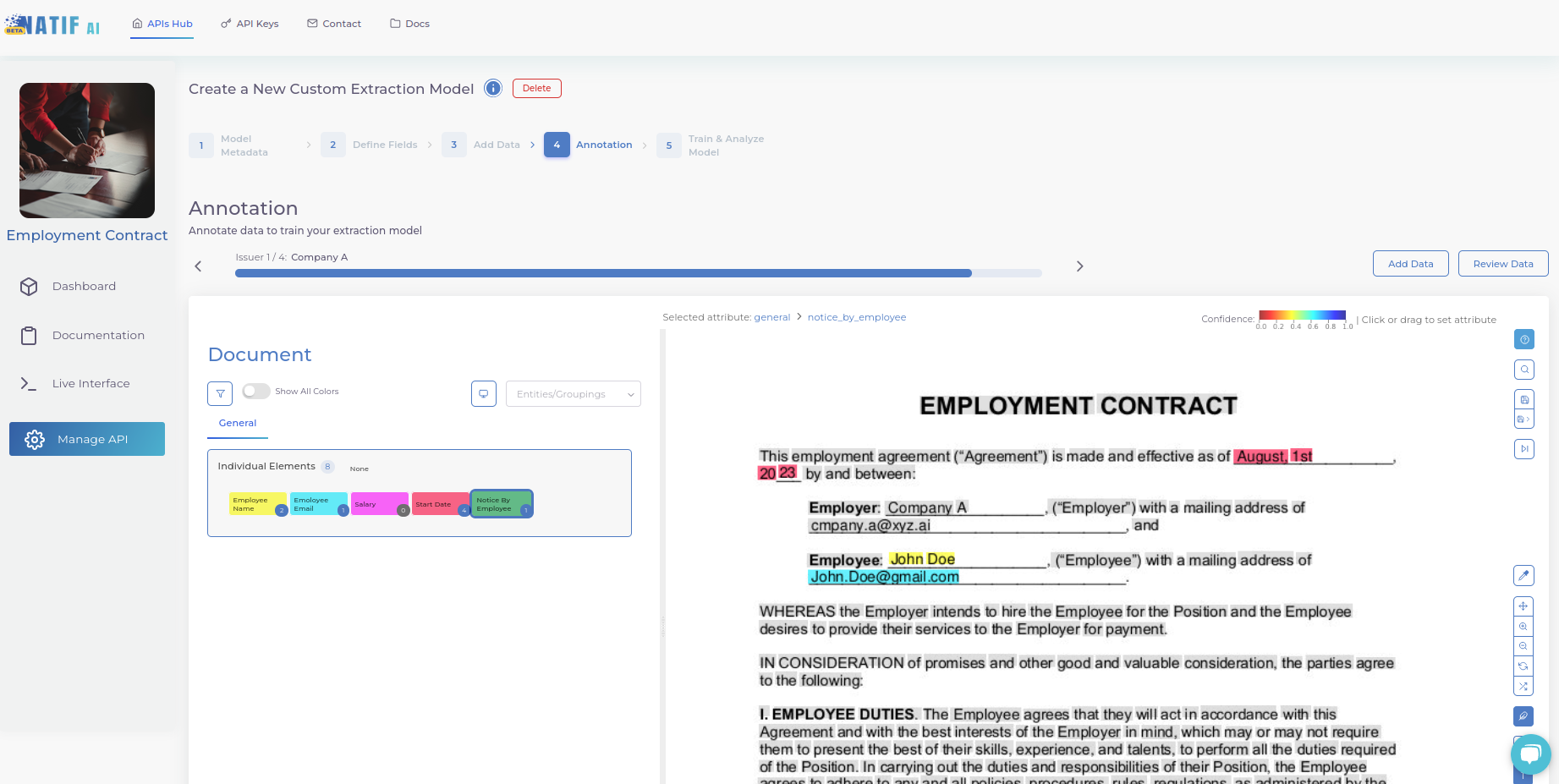
4. Annotieren Sie Ihre Dokumente
Unser Annotationstool erfasst den gesamten Text Ihrer Dokumente mithilfe unserer hochwertigen OCR (optischen Zeichenerkennung).
Als Nächstes müssen Sie den einzelnen Wörtern/Sätzen nur noch die entsprechenden Bezeichnungen zuweisen. Wählen Sie dazu die Entität aus der Liste auf der linken Seite und dann die Wörter, die diese Entität darstellen, auf der rechten Seite aus.
Ein Popup-Fenster zeigt Ihnen, wie Sie effizient durch das Annotationstool navigieren können.
Wenn Sie mit der Annotation des aktuellen Dokuments fertig sind, speichern Sie es und fahren Sie mit dem nächsten Dokument fort, bis Sie alle hochgeladenen Dokumente annotiert haben.
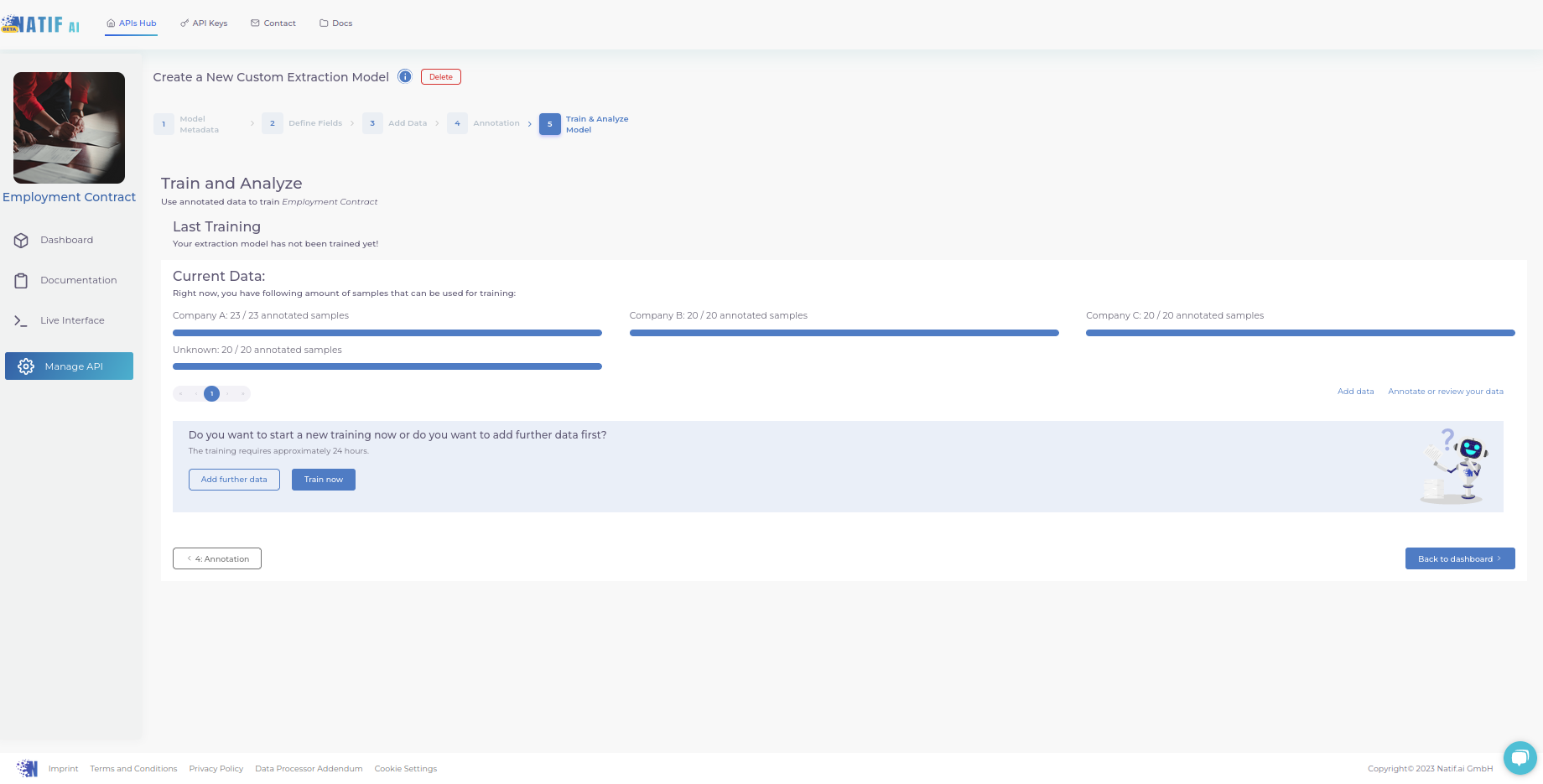
5. Starten Sie das Training
Nun haben Sie es fast geschafft!
Klicken Sie einfach auf „Train now“ und warten Sie darauf, dass Ihr Modell anhand Ihrer annotierten Dateien trainiert wird.
Sie können jedoch bereits mit der Integration der API beginnen. Die Ergebnisse sehen Sie, sobald das Modell das Training abgeschlossen hat – dazu bekommen Sie von uns eine Info per Mail.
So trainieren Sie Ihr eigenes Extraktionsmodell für jede Art von Dokument!
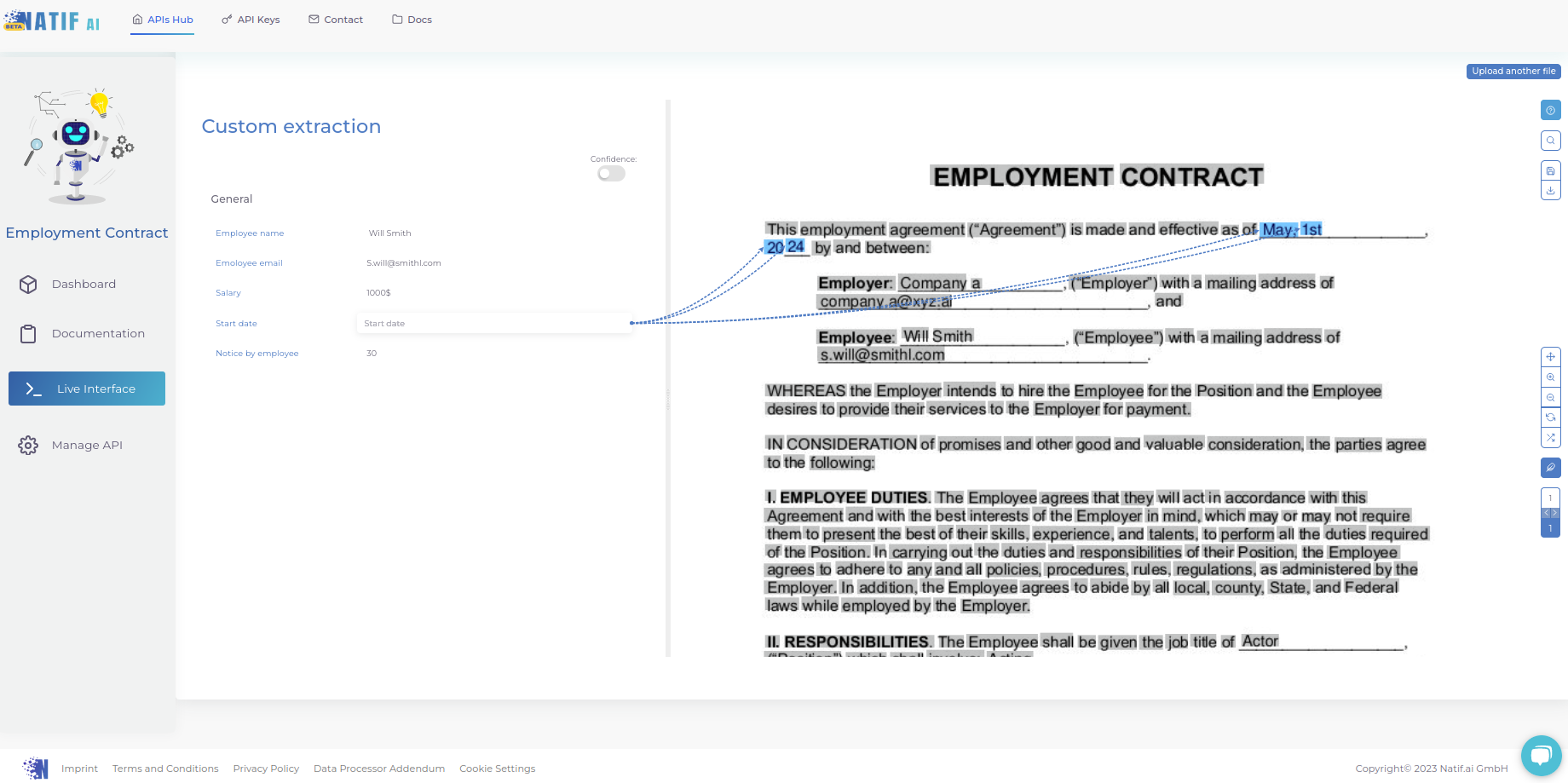
Ihr trainiertes Modell können Sie auch im Live-Interface testen, in dem Sie eine Liste der extrahierten Entitäten sehen. Dazu einfach auf eine Entität klicken und ein Pfeil zu allen Instanzen erscheint.