Die Verarbeitung von Dokumenten wie bspw. Rechnungen, Kontoauszügen oder Lieferscheinen kann oft sehr komplex werden, da die reine Extraktion einzelner Datenfeldern nicht mehr ausreicht. Meist gehören Daten einer gemeinsamen Gruppe an oder stehen in einer hierarchischen Beziehung zueinander.
So sollten bspw. bei der Extraktion von Rechnungsinformationen alle Angaben zu einem Artikel auch genau diesem zugeordnet werden.
Dass Sie auf unserer Plattform Ihr eigenes Extraktionsmodell trainieren können, ist nichts neues mehr. Ab sofort können Sie aber auch genau solche komplexen Dokumententypen trainieren und genau solche Beziehungen selbst definieren.
Wir erklären Ihnen hier Schritt für Schritt den Weg zu Ihrem individuellen Extraktionsmodell.
Falls Sie bisher noch kein eigenes Modell trainiert haben, finden Sie in diesem
Blogbeitrag alle grundlegenden Informationen.
Schritt 1: Metadaten festlegen
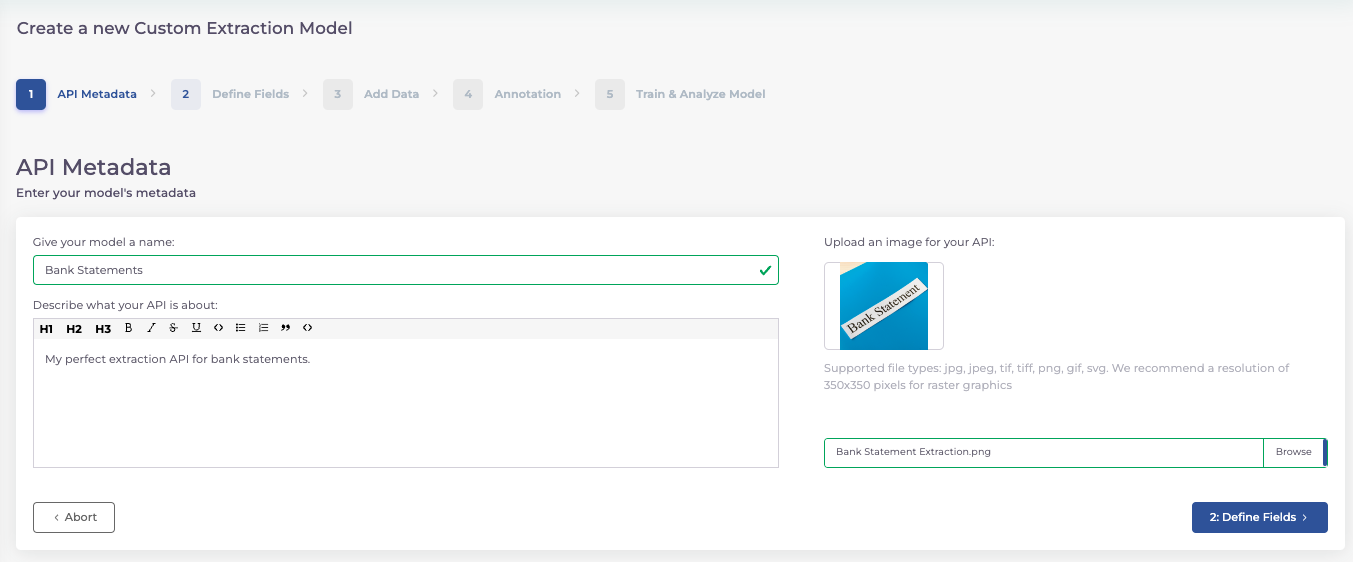
Im ersten Schritt können Sie die grundlegenden Informationen Ihres Modells bestimmen. Dazu tragen Sie einen Namen und eine Beschreibung ein und laden ein passendes Bild hoch. Diese Angaben dienen dazu, dass Sie Ihr Modell später von den anderen unterscheiden können.
Schritt 2: Datenfelder definieren
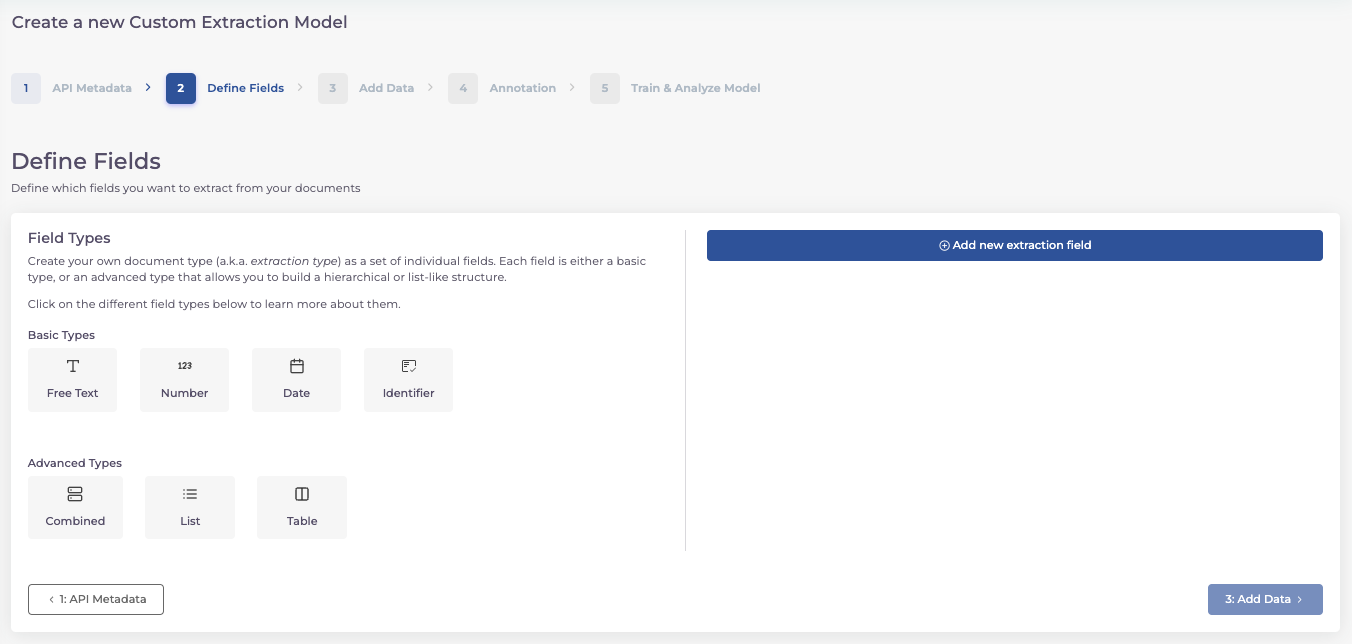
Bei der Definition der Datenfelder können Sie zwischen unterschiedlichen Feldtypen wählen.
Basic Types
Die Basic Types geben die Art des Datenfeldes an. Sie bestimmen also, ob der Inhalt ein Text (z.B. Name), eine Zahl (z.B. Alter), ein Datum (z.B. Geburtsdatum) oder eine Kennung (z.B. IBAN) ist.
Jedem einzelnen Feld wird demnach ein Basic Type zugeordnet.
Advanced Types
Als Advanced Types werden die Gruppen von Datenfeldern bezeichnet. Jedes Mal, wenn Sie also eine Beziehung oder Zugehörigkeit mehrerer Datenfelder haben, wählen Sie einen der Advanced Types aus. Diesem Advanced Type können Sie dann die entsprechenden Datentypen, also Basic Types, zuordnen.
A. Combined:
Combined Types dienen der hierarchischen Gruppierung mehrerer Felder. So kann man zum Beispiel einen Combined Type für die „Gesamtbeträge“ definieren, welche je ein Feld für den „Bruttobetrag“, „Nettobetrag“, „Steuerbetrag“, und „Steuersatz“ vorsieht. Alle Subfelder in diesem Beispiel wären vom Basic Type „Number“.
B. List:
Mit einer List können sie eine Liste von Elementen statt Einzelwerten extrahieren. Sie können eine Liste von Basic Types erstellen (wenn Sie bspw. mehrere Bestellnummern in Ihren Dokumenten haben) oder eine Liste von Combined Types (falls sie beispielsweise mehrere Bankverbindungen mit je IBAN und BIC extrahieren möchten).
C. Table
Eine Table gruppiert, wie der Name schon sagt, die Inhalte von tabellarischen Daten. Häufig werden Artikel als mehrere Zeilen in einer Art Tabelle dargestellt. Für diese würde man eine Table namens „Artikel“ anlegen. Die Table besteht dann aus dem Combined Type, welcher aus Feldern für die „Bezeichnung“, „Anzahl“, „Preis“, etc. aus Basic Types besteht.
Hinweis: Prinzipiell können sie anstatt einer Table auch eine Liste von Combined Type wählen, da die beiden äquivalent sind.
Beispiel: Extraktion von Kontoauszügen
In unserem Beispiel möchten wir eine Extraktion für Kontoauszüge trainieren. Dazu möchten wir alle Informationen zu Kontoinhaber, Bank, Kontostand, Datum sowie den Buchungsdetails extrahieren. Unsere definierten Datenfelder sehen wie folgt aus:
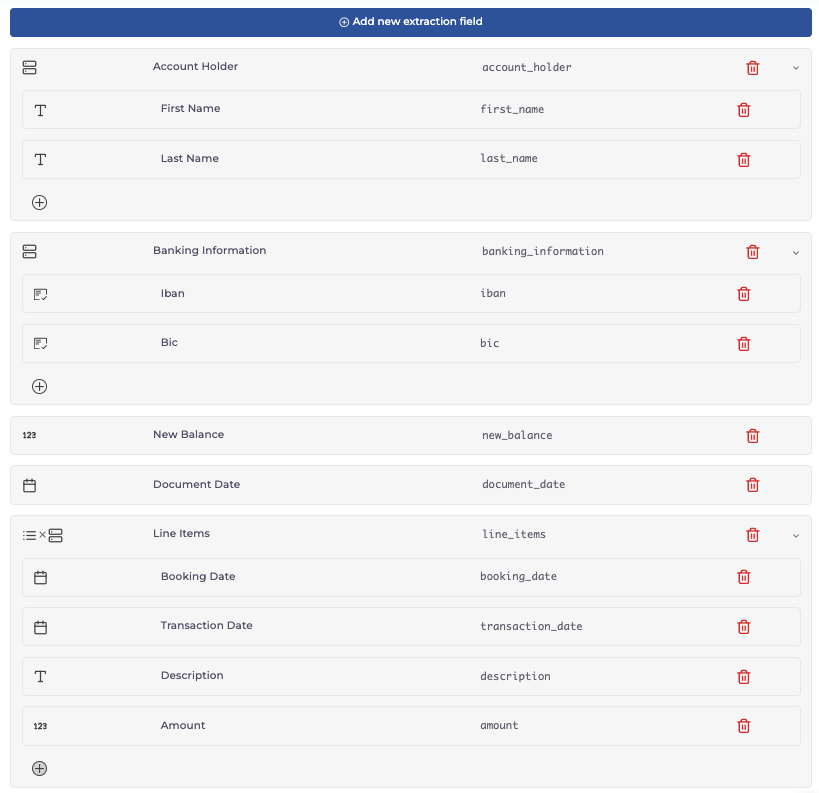
Schritt 3: Trainingsdaten hochladen
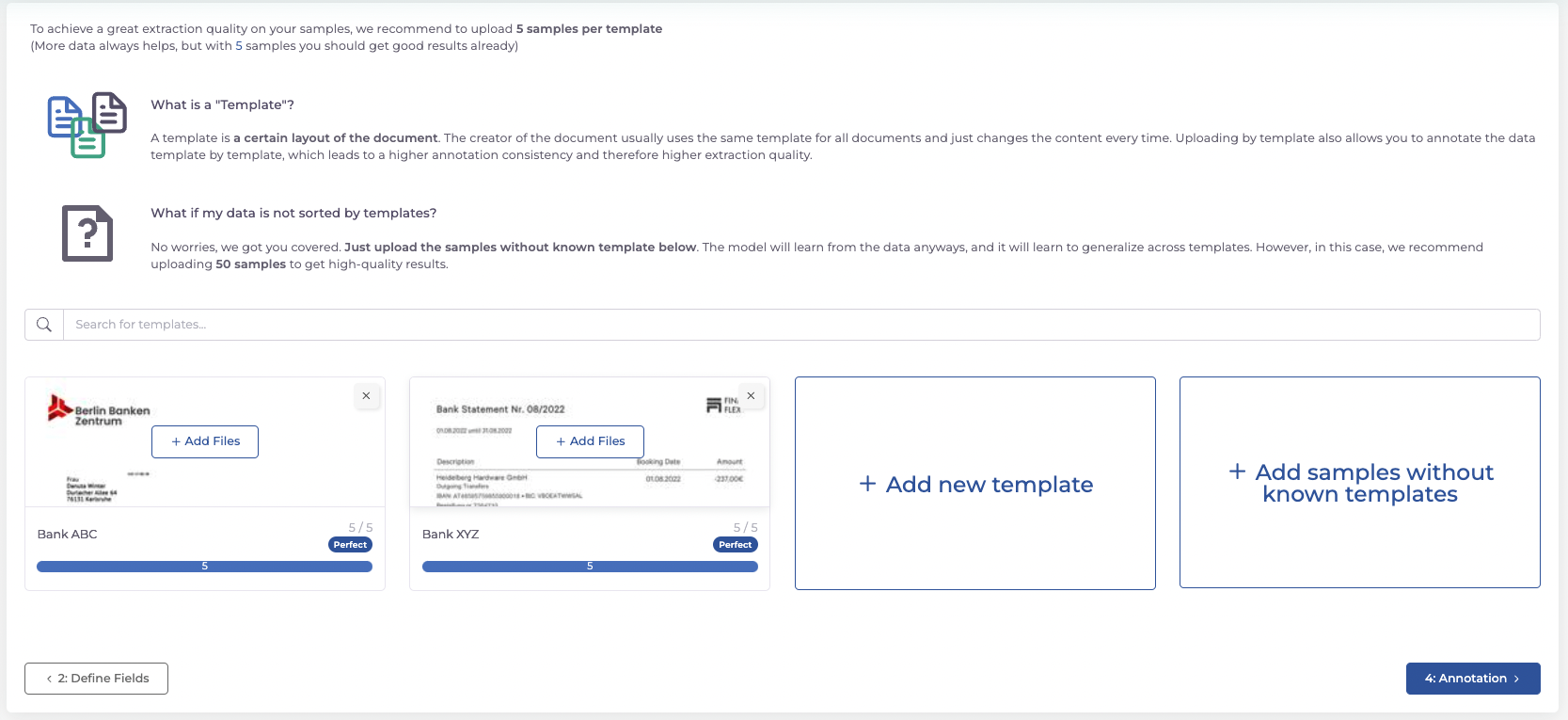
Damit das Modell lernt unsere Dokumente zu verstehen, laden wir im nächsten Schritt ein paar Trainingsdaten hoch. Sie können die Dokumente einzeln pro Template oder gemischt hochladen. Als Template wird das Layout eines Dokuments bezeichnet – wenn Sie also Kontoauszüge von drei unterschiedlichen Banken erhalten, können Sie pro Bank ein Template erstellen.
Es ist zu empfehlen mindestens fünf Dokumente pro Template hochzuladen, damit die KI ausreichend trainiert werden kann.
Schritt 4: Dokumente annotieren
Im nächsten Schritt annotieren wir die hochgeladenen Dokumente. Damit zeigen wir der KI, an welcher Stelle sich welche Datenfelder befinden. Dieser Schritt ist sehr wichtig und sollte sorgfältig durchgeführt werden, da die Daten zum Training genutzt werden und somit direkten Einfluss auf die Qualität des Modells haben.
Die Plattform führt Sie Template nach Template durch die hochgeladenen Dokumente. Zur Annotation wählen Sie links ein Datenfeld und anschließend die entsprechenden Textboxen im Dokument. Haben Sie alle Datenfelder einer Kategorie hinzugefügt, können Sie diese abschließend gruppieren (die Plattform schlägt Ihnen die Gruppierung bereits vor).
Nachdem Sie das Dokument fertig annotiert haben, können Sie es mit dem „Save and Next“ Button rechts in der Toolbar speichern und mit dem Dokument nächsten fortfahren.
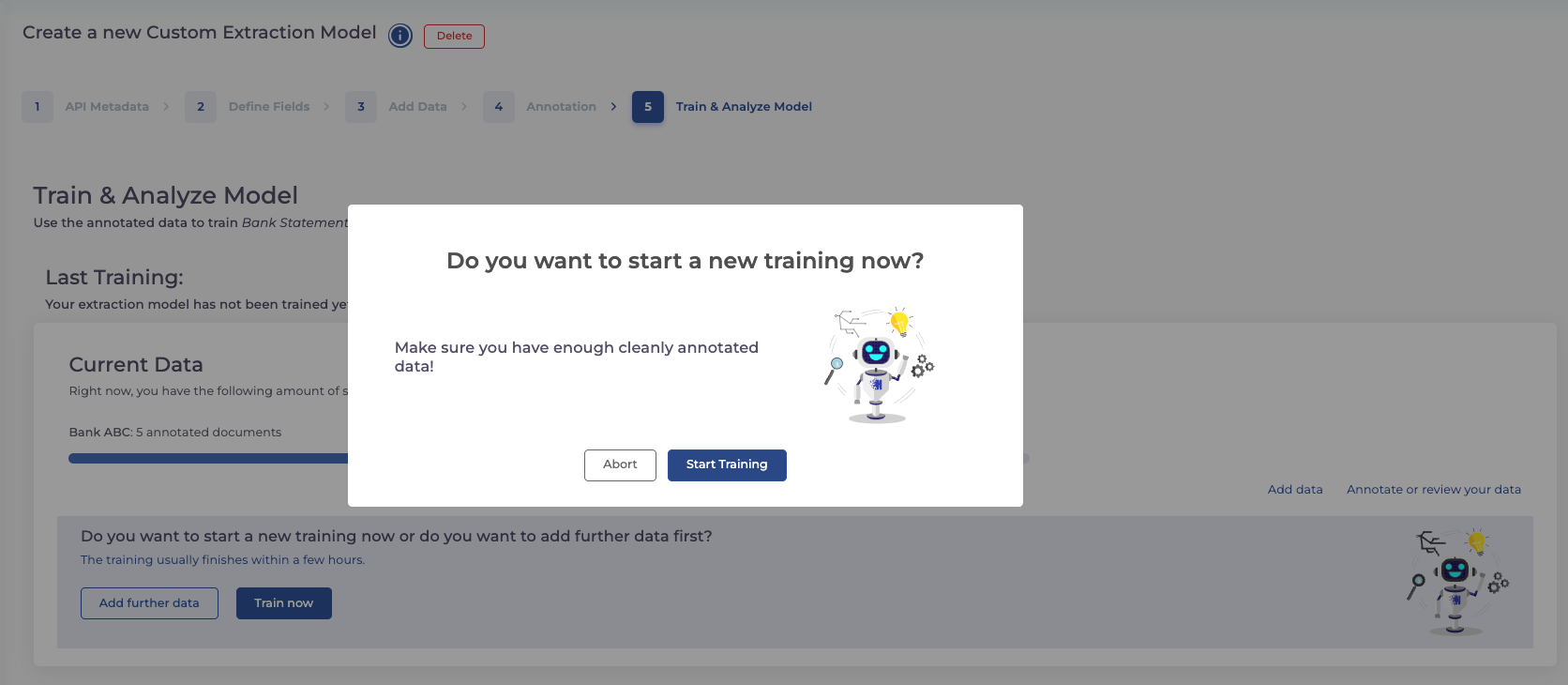
Schritt 5: Training Starten
Haben Sie alle Dokumente annotiert, können Sie Ihr Training starten. Bis das Training abgeschlossen ist, können Sie Ihre API bereits integrieren. Alle Informationen dazu sowie Code Snippets finden Sie in der Dokumentation.
Et Voilá! Ihr eigenes Extraktionsmodell ist einsatzbereit und kann direkt genutzt werden!
Falls Sie Fragen haben oder Unterstützung benötigen, zögern Sie nicht uns zu
kontaktieren oder ein Meeting mit unseren KI-Experten zu vereinbaren.